在开始正文之前,首先要感谢UnitedStack工程师朱荣泽对这篇博文的大力帮助和悉心指教。本文主要针对UnitedStack公司在巴黎峰会上对Ceph可靠性的计算方法(https://www.ustack.com/blog/build-block-storage-service/)做了一个更明确的分析和阐述,供对此话题感兴趣的朋友一起来讨论、研究,文章中如果有不当之处,还请各位高人指教。
什么情况下数据会丢失?
这个话题的另外一种提法就是存储的可靠性,所谓存储的可靠性最基本的一点就是数据不要丢失,也就是我们俗称的“找不回来了”。所以,要分析Ceph的可靠性我们只需要搞清楚,到底在什么情况下我们的数据会丢失,并且再也无法恢复,基于此我们便可以创建我们的计算模型。
我们先来假定一套简单的Ceph环境,3个OSD节点,每个OSD节点对应一块物理硬盘,副本数为3。那么我们排除MON的因素影响Ceph集群的运行的问题,显而易见,当三个OSD对应的物理硬盘全部损坏时,数据必然无法恢复。所以此时集群的可靠性是与硬盘本身的可靠性直接相关。
我们再来假定一套更大的Ceph环境,30个OSD节点,分3个机架摆放,每一个机架有10个OSD节点,每个OSD节点仍然对应一块物理硬盘,副本数为3,并且通过CRUSH MAP,将每一份副本均匀分布在三个机架上,不会出现两份副本同时出现在一个机架的情况。此时,什么时候会出现数据丢失的情况呢?当三个机架上都有一块硬盘损坏,而恰恰这三块硬盘又保存了同一个Object的全部副本,此时数据就会出现丢失的情况。
所以根据以上的分析,我们认为,Ceph的可靠性的计算是与OSD的数量(N)、副本数(R)、每一个服务节点的OSD数量(S)、硬盘的年失败概率(AFR)。这里我们使用UnitedStack相关参数进行计算。
具体取值如下图所示:

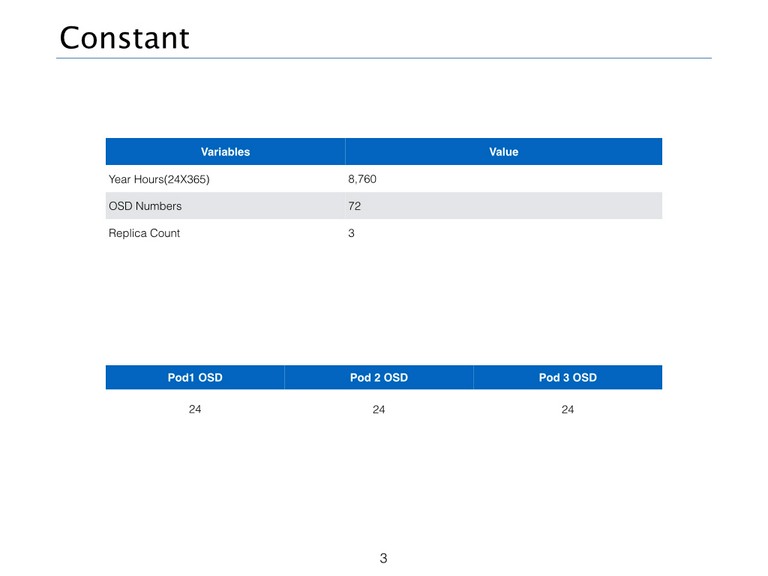
硬盘年失败概率
根据维基百科的计算方法(http://en.wikipedia.org/wiki/Annualized_failure_rate),AFR的计算方法如下:

例如,计算Seagate某企业级硬盘的AFR,根据文档查到MTBF为1,200,000小时,则AFR为0.73%,计算过程如下:

但是,根据Google的相关计算,在一个大规模集群环境下,往往AFR的值并没有硬盘厂商那样乐观,下面的统计告诉了我们在真实环境下AFR变化的情况:
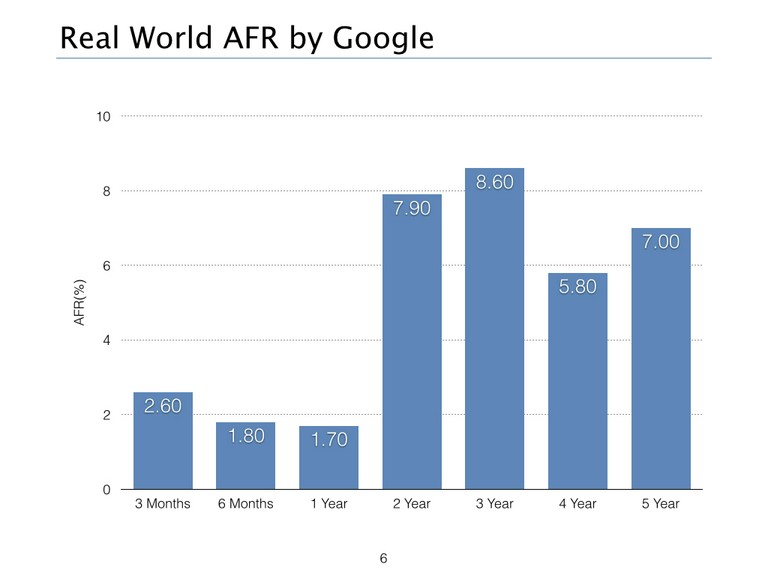
所以我们可以看到实际的AFR的变化范围随着年份而变化,取值范围在1.7%-8%左右,所以本文中AFR为1.7%。
硬盘在一年之内损坏的概率
有了AFR,我们就可以尝试计算硬盘在一年中出现故障的概率,根据相关研究,硬盘在一定时间内的失败概率符合Possion分布(已经把知识还给老师的同学请移步:http://en.wikipedia.org/wiki/Poisson_distribution)。具体的计算公式为:

当我最初拿到这个计算公式时,一下子懵了,到底该如何确定数学期望值lamda呢?
lamda的计算过程
根据相关的研究资料,单块的硬盘损坏的期望值(Failures in Time)是指每10亿小时硬盘的失败率(Failure Rate λ),计算过程如下:

这里的Af(Acceleration Factor)是由测试时间乘以阿伦尼乌斯方程的值得出来的结果,好吧,我承认,我也是现学现卖,这个方程式是化学反应的速率常数与温度之间的关系式,适用于基元反应和非基元反应,甚至某些非均相反应。不过可以看出Failure Rate的计算过程实质主要是计算环境因素引起的物理变化,最终导致失败的数学期望值。所以根据相关研究,最终FIT的计算方法为:

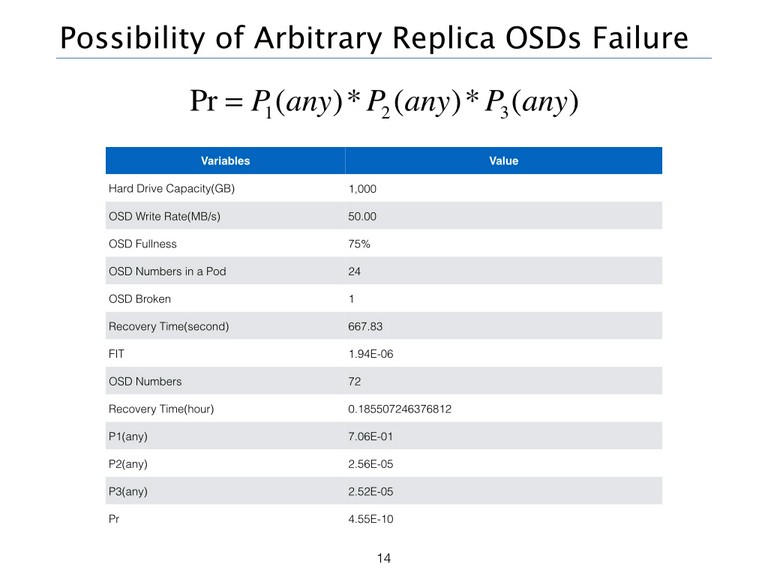
有了这些参数后,我们就可以开始正式计算Ceph集群中,不同机架上有三块硬盘同时出现损坏的概率啦。
任意一个OSD出现损坏的概率P1(any)
我们不太容易直接去计算任意一个OSD出现损坏的概率,但是我们很容易计算没有OSD出现问题的概率,方法如下,用一减去无OSD节点出现问题的概率,得到P1(any)。

在恢复时间内第二个节点出现故障的概率P2(any)
我们知道当Ceph发现一个有问题的OSD节点时,会自动的将节点OUT出去,这个时间大约为10min,同时Ceph的自我修复机制会自动平衡数据,将故障节点的数据重新分配在其他的OSD节点上。
我们假设我们单盘的容量为1000 GB,使用率为75%,也就是此时将有750 GB的数据需要同步。我们的数据只在本机架平衡,节点写入速度为50 MB/s,计算方法如下:

注意:由于每个节点有三个OSD,所以要求每台物理机所承受的节点带宽至少要大于150 MB/s。并且在这个计算模型下,并没有计算元数据、请求数据、IP包头等额外的信息的大小。
有了Recovery Time,我们就可以计算我们第二个节点在Recovery Time内失败的概率,具体的计算过程如下:

在恢复时间内第三个节点出现故障的概率P3(any)
计算方法同上,计算过程如下:

一年内任意副本数®个OSD出现故障的概率
所以将上述概率相乘即可得到一年内任意副本数®个OSD出现故障的概率。
Copy Sets(M)
在这个计算模型中,因为任意R个OSD节点的损坏并不意外着副本的完全丢失,因为损坏的R个OSD未必保存着一个Object的全部副本信息,所以未必造成数据不可恢复,所以这里引入了Copy Sets的概念。简单来说,Copyset就是存放所有拷贝的一个集合,具体的定义和计算方法可以查看参考链接。那么这里的场景下,Copy Sets为三个机架OSD数量相乘,即M=242424。当然如果是两个副本的情况下,M应该为2424+2424+24*24。

CEPH的可靠性
所以最终归纳出CEPH可靠性的算法为:
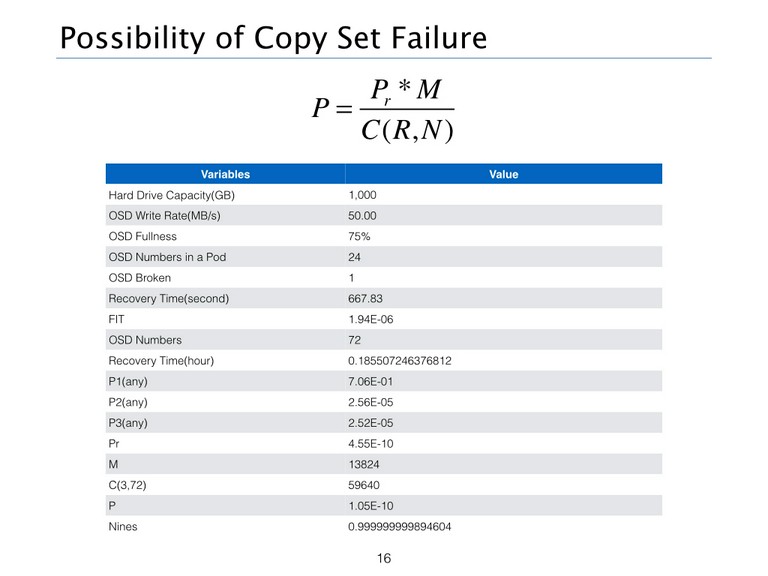
可以看出Ceph三副本的可靠性大约为9个9,由于Recovery Time和AFR取值的问题,所以计算结果和UnitedStack上略有出入。