The reason why I do benchmarks is that, in my experience, many recommended settings are effectively myths. Many are perfectly fine, but a surprisingly large part either was never quite true or is based on data that got obsolete for various reasons (e.g. changes in hardware or software). So the verification of the facts is rather imporant to make good decisions, which is why I've been recently benchmarking file systems available on Linux, briefly discussed in the posts on EXT4 vs. XFS, BTRFS and Reiser.
In this post, I'd like to briefly look at a potential myth when it comes to databases and I/O schedulers. The purpose of the scheduler is to decide in what order to submit I/O requests (received from the user) to the hardware - it may decide to reorder them, coalesce requests into larger continuous chunks, prioritize requests from some processes etc.
Linux currently (kernel 4.0.4) offers three schedulers (there used to be anticipatory scheduler, but it got removed in kernel 2.6.33):
- cfq (default) - attempts to do "completely fair queueing" for various processes, with the possibility to lower/increase priority of some processes using
ionice, and also applies a fair amount of magic (reordering, coalescing etc.) - noop - probably the simplest scheduler, pretty much just a FIFO with trivial merging of requests
- deadline - attempts to guarantee start time of serving the request, prioritises reads over writes and performs various other things
I'm not going to discuss cfq here - it's a fairly complex scheduler attempting to reorder the requests in various ways, support priorities, different handling for synchronous and asynchronous requests and such. Instead, let's look at the simpler scheduler and why they might work better in some cases.
deadline
The usual wisdom used to be that for databases, deadline scheduler works best. The reasoning behind this recommendation is quite nicely explained for example here, but let me quote the main part:
This tends to reduce the merging opportunity for reads as they are dispatched quicker, but enhances merge opportunity for writes since they hang around longer within the scheduler. Also this means read latency is enhanced while write latency often increases.
In other words, databases generally care about latency of reads, as that's what the user has to wait for, and moreover those reads are usually random, so attempts to coalesce them are rather futile and increase the latency for no gain. OTOH writes are usually initiated by backend processes (e.g. during a checkpoint) and often are sequential, so it's worth reordering them and such - the latency is not that critical as the user won't observe it.
So the deadline scheduler performs only minimal processing of read requests (because it's futile anyway) but attemps to optimize write requests in exchange for higher latency. This should well when the workload is read-mostly, but if the user modifies any data, the COMMIT has to wait for completion of the write request (and is thus subject to the increased latency).
noop
From time to time, people are also recommending noop which does very little processing and instead tries to forward the requests to the lower layer - usually a RAID array or SSD device, but often a hypervisor in virtualized environment.
For RAID arrays, this is supposed to work better because as the OS has pretty much no idea of the geometry, so it can't say whether two requests are adjacent (on the same spindle) or will end up on two different devices. This is also true for virtualized environments.
For SSD devices, the reasons are different. The reordering/coalescing the requests is exploiting the difference between processing random and sequential requests on rotational storage, but on SSDs this difference is mostly (but not entirely) gone. Another thing is that SSD devices are effectively RAID arrays built from smaller SSD with parallel channels, so the previous point also applies to some extent.
tunables
It's also worth mentioning that all three schedulers allow additional configuration (cfq, deadline and noop), but it's quite low-level and difficult to tune, so people only rarely use it.
Most people simply switch scheduler for a device
$ echo 'noop' > /sys/block/sda/queue/scheduler
and thats's all.
benchmarks
I've done a bunch of pgbench benchmarks with tuned ext4 on a SSD (Intel DC S3700 100GB). Nothing special - multiple 30-minute runs for each combination of these parameters:
- read-only vs. read-write
- data set size [150MB, 2GB and 16GB]
- number of clients to benchmark scalability (1,2,4,8,16)
If you don't know pgbench, it's a stress test performing a lot of random read and writes.
For the read-only workloads, I've measured absolutely no difference in throughput above ~1%, so I'm not even going to show it here. It is possible that other filesystems would show some difference, but I find that rather unlikely (although I plan to test it).
In read-write benchmarks the schedulers really do perform differently - on the small data set the differences are tiny, so let's look at the medium
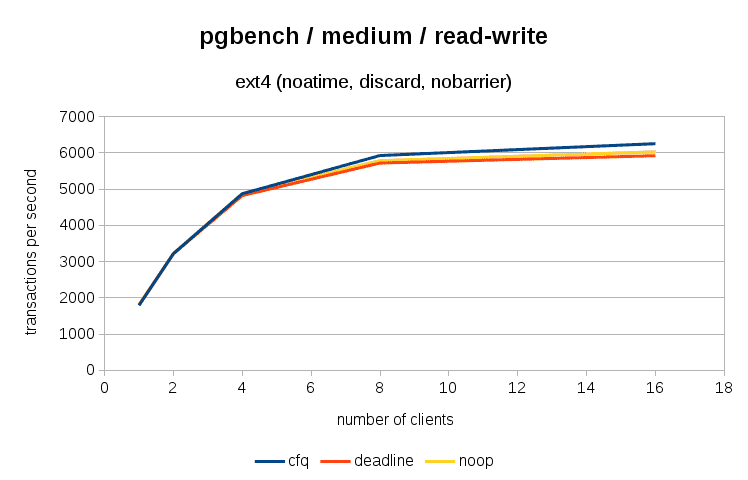
and large case
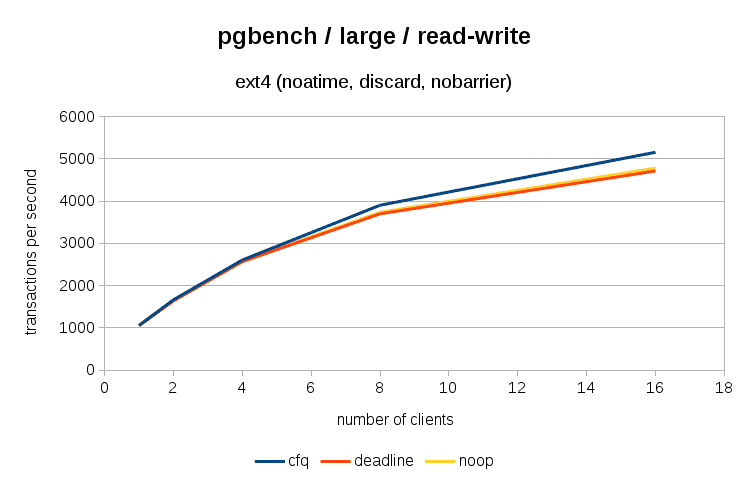
The overall differences are not extreme but certainly significant
| scheduler | tps | average latency (ms) |
|---|---|---|
| cfq | 5098 | 3.138 |
| noop | 4728 | 3.384 |
| deadline | 4656 | 3.436 |
Yes, when it comes to total throughput and average latency, cfq performs about 10% better than both other schedulers.
But total throughput is often exchanged for higher average latency and/or latency variance. The previous table shows that cfq has the lowest average latency, but let's see how it evolves during the 30-minute run on the large data set (with 1-second resolution). Notice that the next two charts use log-scale for y-axis.
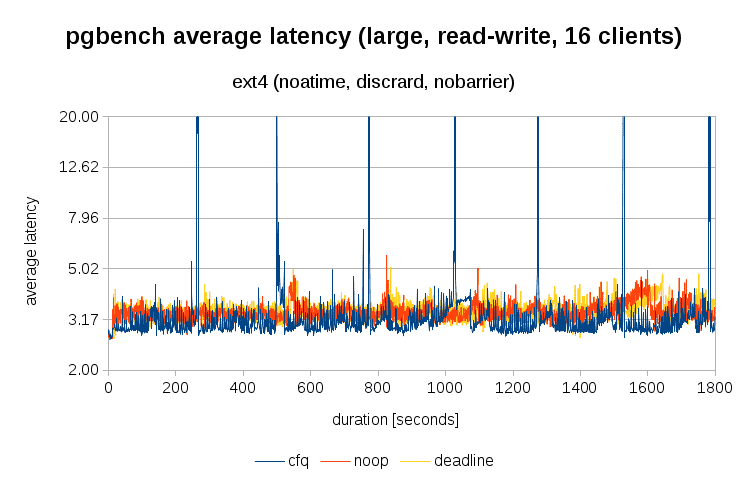
This mostly matches the results from the table - cfq (blue) is mostly below noop (red) and deadline (yellow). It's however worth noticing the spikes that only happen with cfq - it's likely a due to having to process a lot of full page writes right after starting a checkpoint. The processing performed by cfq seems to be quite expensive and impacts latency.
Let's also see standard deviation of latency (again with 1-second resolution):
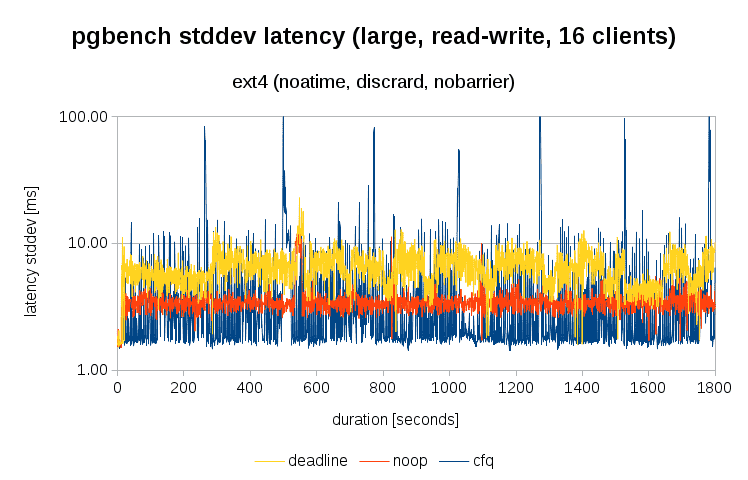
OK, here cfq performs slightly worse - most of the time it's better than both noop and (especially) deadline, but it's much less variable and on some cases (matching checkpoints) it gets slightly worse.
Summary
While cfq seems to perform better in this particular benchmark, I wouldn't dare to claim that the recommendations to use noop or deadline schedulers are nonsense. Firstly, I wouldn't dare to claim that based on a single benchmark - it seems perfectly possible that on other types of storage (e.g. large RAID arrays or rotational devices) the other scheduler might work better. Secondly, while cfq gives the best throughput, the behavior with other schedulers (especially noop) is slightly smoother.