导读
对于社交、媒体关系网络实体,最终给用户展示的是各个实体关系及属性的聚合结果,传统关系型聚合更新是非常难解的,因为涉及多张表进行级联查询,同时关系网络或属性实时变更,要触达周边关系的消息通知,引发性能差和编程上高复杂性。
优酷也同样如此,视频内容数据天然呈现巨大的网络结构,各类数据实体连接形成了数十亿顶点和百亿条边的数据量。我们的解法采用图来组织更新联动,利用子图来实现复杂关系网络的组织,多个子图的协同形成实现秒级的更新千万级的属性更新。本次分享将从图谱化更新的视角,重新去组织内容数据的更新,给你带来全新的视角来诠释图谱化在业务更新场景的应用。
主要内容包括:
- 分发侧数据实时更新现状和挑战
- 图架构核心技术探索
- 图谱化在内容更新上应用
- 系统实践经验分享
01 分发侧数据实时更新现状和挑战
图1是用户在优酷app端和pc端看到的产品展现形式,在用户 ( 人 ) 视角上关注”搜得着、看得见”,通过结果页内容展示如视频名称、节目卡信息——角色、演员、剧集、简介等,以及互动数据——评论、分享、踩等,进而决策是否看这个内容。从内容 ( 货 ) 生产侧看,除了内容制作编辑外,就是内容的管理,这些内容通常由不同的实体平台构成,如对UP主管理,内容管理,节目资料页管理,人物管理等等组成的一个复杂且分工明确的系统。从场景视角 ( 场 ) 如何以将这些内容组装后以高效、简单的方式传递给对用户,这三者关系就形成互联网典型的人-货-场的局面。从数据组织这个维度看,内容平台关系天然就形成一个有很多实体和关系网络结构。
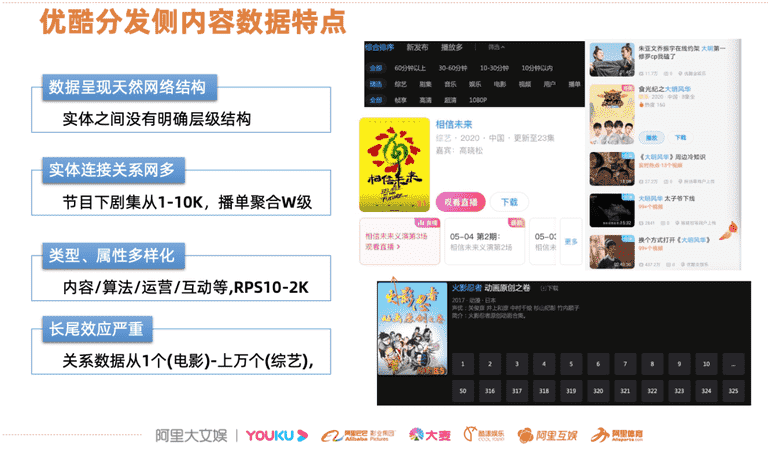
图1 优酷分发侧内容数据特点
如前面所说在内容化产品中,实体进行分类后形成多种类型,如节目,视频,播单等等,类型之间有很多关系网络连接起来。图2是一个简单的示意图,节目下挂载多个人物,这些人物会进一步细化很多职能关系,如导演、嘉宾、角色、编剧等,而节目本身有归属类目,而这一类的节目在打包后,形成了聚合包,这些不同实体的有机组合便形成了复杂的网络结构。直接在客户端去实时查询这些实体数据来组织内容,显然在时延上是无法接受的。这样内容数据就需要在后端进行按既定的编排,构建进入索引中,对于更新链路上带来的挑战,每个节点的更新都会触发周边节点的更新。比如图2下方节点,在取具体某个人物关系能达到约4w次并发量,传统的数据流的架构模式,在面向复杂网络数据链路处理上面临很多问题。
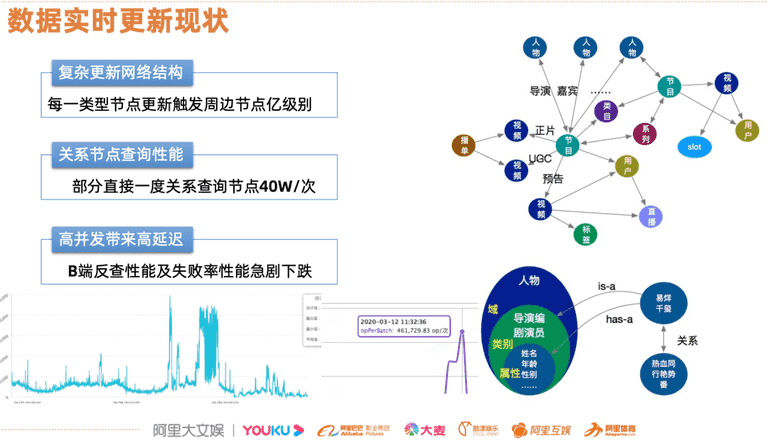
图2 数据实时更新现状
图3给出基于数据流的架构,输入侧是业务系统 ( 产品、运营、户上传的内容 ),这些内容会存储到各自业务数据库中。全量构建索引,是将数据全量同步 ( 如mysql dump到hadoop上 ) 通过ETL加工关联构建索引消息表,增量部分,在数据更新到数据表后下发变更增量消息 ( 如mysql数据库比较典型bin-log,拉取数据库的分量消息 ),由下游系统通过增量补齐完整的数据进行实时更新。结合内容平台业务我们发现数据流在任一实体中都有可能会出现分叉。一个用户节点的更新 ( 如名称、状态 ) 触发用户归属的视频联动更新,视频的更新又涉及到聚合内容的联动。这种链式传导在性能上会引发单点消息的增加呈现级数增加,多路游走给系统带巨大的压力。增量更新在时效性上需要秒级更新反馈到线上,而在更新过程反查服务面向B端服务,特点是运营系统,QPS无法支撑级联join引发的查询。特别在互动、播放、粉丝等的互动数据,组合分叉会导致无效的查询,后端整体系统性能压力大,严重的会引发后端业务系统无法正常提供服务。基于性能优化、可维护性、可修改性方面考量结合业务特点,提出图这种架构思路来解决实际业务问题。
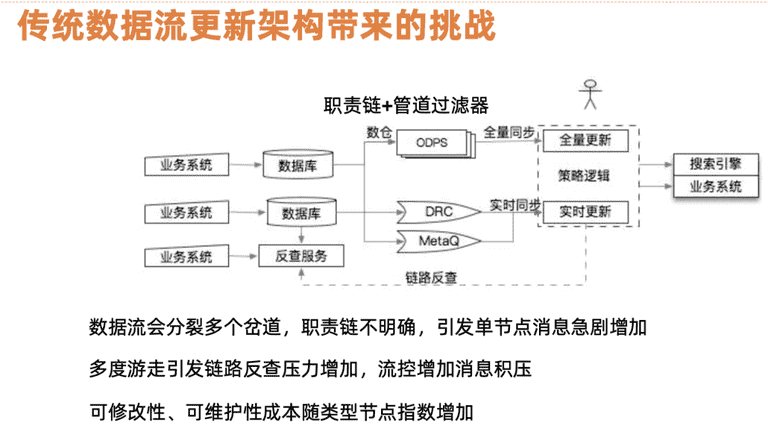
图3 传统数据流更新架构带来的挑战
02 图架构核心技术探索
图架构的核心点,图结构和图存储。这里有两个概念:知识图谱,图数据库。
这里讲下图数据库里面的建模,业内图建模有两种:
( Resource Description Framework,RDF ) 是个3元组,典型的是Neo4J,面向知识图谱的数据库,另一种是标签属性图 ( Labeled Property Graph,LPG ),RDF是W3C标准,而LPG是工业标准,受到广大图数据库厂商的广泛支持,有一个惟一的顶点,外围延伸出很多边属性,属性在数据库中是一列一列的字段,数据库有唯一主键,主键就是顶点的属性值。实际业务场景中我们考虑LPG模式,因为RDF 在实际的图更新场景中有局限 ( RDF不能唯一地标识相同类型关系的实例、无法鉴定关系实例等 ),而且图存储比较直观,如何把百亿级的图数据库,如整个视频库 ( 有上亿台数据 ) 和P台机器,切分成小子图,从工程角度会考虑负载均衡和带宽的问题。业内这种算法比较多,主要有两种模式:切边和切顶点。先把一个大的图按照一定的方式切割,小的点上有两种模式。无论是切边还是切顶点,都有对应的复杂度,都是采用切边的模式,使得节点均匀、边切割最少。这种方式,在整个业务场景看,并不是越复杂、就越有效的。

图4 知识图谱和图数据库
1.图架构技术探索之路
图架构选型上探索过程。最为核心一点:一切从需求出发。场景上考虑规模和高性能,需要支持亿级别的节点实时更新,在整个更新链路中,关系、边上流量较大,存上百甚至上万不等的规模。在可用方面,节点的导入、导出上希望用户能指定顶点和边, 方便用户灵活构图。整个图数据库选型过程中,参考了开源的JanusGraph,hdb,底层都是用原生的Hbase来存储,这种存储的特点是:顶点和边是内部可以指定的,面向用户是黑盒,业务场景上是一个读写密集型,如批量导入和导出,和Hadoop集群、Flink实现无缝的衔接,数据要很快导入到图中。
总结下,选型上有4点考虑:架构稳定性、生态成熟度 ( 即:社区怎么样,源码贡献度如何,活跃度 )、性能、开放程度 ( 对技术的底层掌握 )。在整个图架构选型过程中,会结合计算引擎、储存引擎、消息管道来形成整体的数据计算通道。计算引擎部分采用的是阿里集团的Blink,存储层没有针对图做深度的存储定制开发,使用集团的Lindorm ( 在阿里云社区中有相关产品介绍,可以理解成hbase的升级版,支持二级索引,在列和簇的使用和api都很友好 )。在这基础上,通过Gremlin–标准的图检索语法,开发 KG ( KeplerGraph ) 图数据库客户端框架。
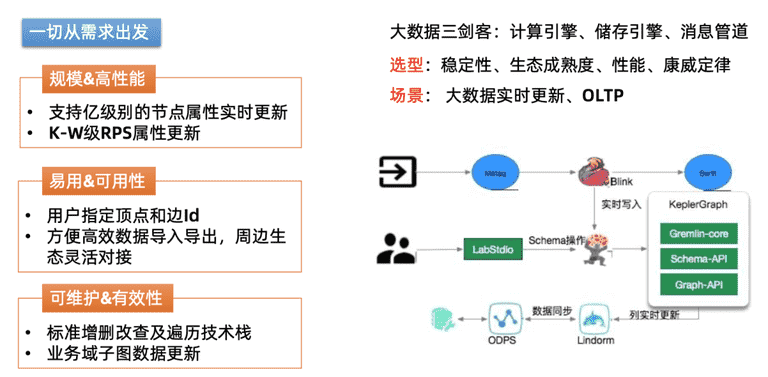
2.图架构关键性设计
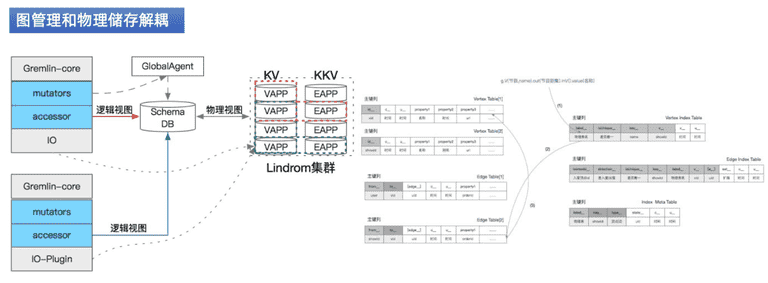
关键设计点,将图管理和物理关系进行解耦,在这个过程中,上游是gremlin-core,提供基础的图检索、查询、更新的语法。执行语法进行解析为逻辑视图。
逻辑视图是KG数据库schema信息表,用来描述数据的数据 ( 元数据 ),可以对元数据做定制,如业务场景中的子域,搜索场景中的页面展示,节目下面有视频,人物等信息。这些信息组装成业务子图,图查询过程中只关心子图信息,在逻辑层进行隔离。全图更新维护的是一张全图,图游走的过程中,要做级联分析策略。开源图数据库,每个数据库都有自己的物理实体存储,子图通过数据冗余的方式组织。更新场景中这种冗余在下游数据中比较多个业务时,存储浪费,难保证一致性,业务耦合度高,基于以上问题,设计逻辑视图。
首先在整个图数据取子图的过程中,通过schema模式维护子图,最终执行通过逻辑子图桥接来操作实际物理的数据,实际过程中把整体的顶点和边进行拆解,顶点K-V表,是数据库的主键和Value信息,KK-V是边表,如节目下面的视频节目id-视频id为主键和Value维持的自身信息,节目排序作为关系标的属性字段存进去。
3.图架构关键性技术
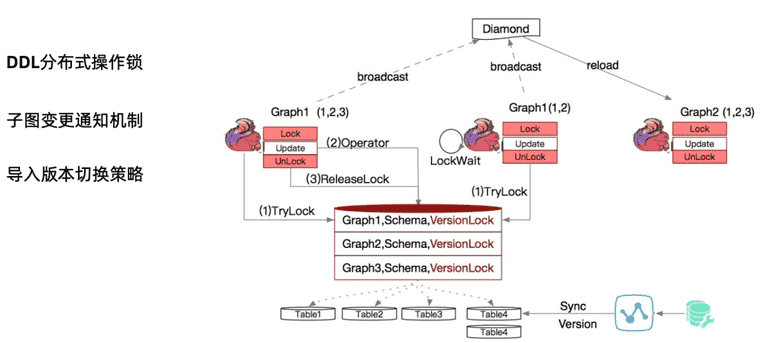
我们看到虽然采用了图的schema 逻辑视图的概念,实际工程实现很快面临如下问题:DDL 分布式操作锁的问题,比如Flink本身是一个集群锁的模式,每个Flink job都维持自己graph,下图中可以看到有G1,当两个Flink实例都操作G1的schema 信息:Flink1要操作T1、T2、T3这三张具体的物理实体表,Flink2实例操作G1和G2两个库。这两个流程同时对schema信息 G2中T1增加一列,传统的两个进程 ( 分布式 ),开始进行相互的数据集更新和锁,我们采用的是WinLock,使用联动的多版本策略,这里增加一列,两个并发进程同时去抢锁,抢到进程的进行DDL操作,操作结束后然后释放。没抢到的是锁等待,等释放后再抢锁操作。采用子图带来复杂性问题,当在一个子图中有更新, 如G2 要操作的数据T1,T2,T3,可能是只读,G1操作中已经有TTL操作,如何通知到G2子图,此时会进行broadcast, 广播策略采用Diamond策略 ( 外部采用zookeeper ),来协调集群间的schema装载过程。
03 图谱化在内容更新上应用
接下来是在整体更新链路上应用。

图中是整个数据存的接入、生产、消费上的整体链路。数据源上分为内容数据和行为数据 ( 如互动数据,播放的微微,标签数据,算法标签信息 )。数据接入后会进行去重,如bin-log中对不同的列和行做操作,会有多条消息,系统对消息流做合并。图关系中的同id会在同一个task中处理,id有来自本体的变更,也有来自周边的消息,两种消息合流时做一次数据去重。数据去重后,接下来有实体关系图,图中标小黑点的部分是一个个的实体,实体外面有很多白点代表实体中的属性,如实体点就是节目id,节目名称、url、海报等信息。灰色点为关系节点,比如两个节目视频之间的关系表,为一个个独立关系表,有自身的属性。图游走的过程会根据关系图,来更新每个白色关系节点、建立新的关系的过程。整个过程都是在Flink中进行的,通过底层的联动KV表中,节目表的更新指向节目数据库中的边表中。一次的更新会涉及多个表的更新模式。上游接口层,采用gremline,编排整个流程的更新,schema层很关键,需要对哪些实体进行接入和更新,由它来负责flink的消息任务,来接收新的消息源数据,用户写这样的插件来进行反查、补全进而完成数据的更新。在内容化的产品中,挂载属性通常是多个。如一个视频的播放量、标题,都归属视频的属性,视频的标题基本上不变,视频的VV会随播放量增加而不断触发,导致我们更新某个属性的时候,热点也存在。针对这一点,进行了diff操作,diff这个节点识别哪些属性和边产生了变化,只对变化边做消息的转发。消息进来之后,进入特征计算,这也是一个计算引擎,面向特征计算的引擎关系篇幅关系,不再赘述。会生成算法上的相关性特征,随着实时下游进入索引更新平台中,进行全自动更新,通过消息管道分发到所有平台上,进而完成数据接入到在整个关系网中的联动和下游特征计算和重新组装,以及线上引擎的流程中。
图谱化在实时数据更新场景技术实现
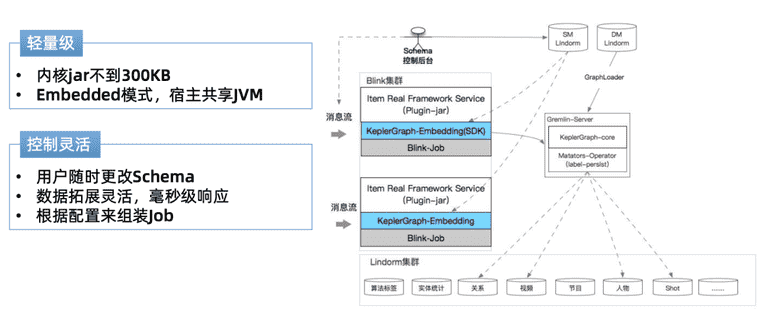
这里采用了Kepler Embeded框架Blink共享JVM,控制灵活,通过schema控制后台,对数据属性更新做灵活的更改,完成后就可响应。然后根据schema 配置组装job。上图是我们的消息流在flink集群上的流转。
04 系统实战经验分享
整个过程中的一些经验和思考。无论在社交领域、视频领域,面临的问题是关系网很复杂,关系数据库没法胜任的,如何探索高效的模式,把数据实时推送、分发到线上。
分解图:把图顶点和边拆解成计算单元,每个实体 ( 节目、视频 ) 一个实体类型,就是一个flink执行的的任务job,负责上游子系统的消息消费。消息完成自身实体和属性的更新后,实体会广播和关联的一度边关系,哪些是实体关注属性,对相应属性进行更新。能够把整个关系网拆解成小子图进行更新。下游的业务侧的诉求很明确,不需要全网信息,只需要部分信息,如UGC、OGC、子频道,不关心系列产品的更新,只关心人物相关的视频信息变更。这样能灵活应用子图模式组装想要的数据。
在边的查询中,有些综艺节目,一个节目有上万个剧集,有的系列下能聚合出上千个节目,按图的查询模式,要查出图中节目的信息,一度节点游走到边,联动底层有上千次查询过程。这个过程中采用一些”反范式”增加冗余,增加顶点属性到边属性中,顶点更新时不仅更新自身的属性,同时更新到边属性上去,这样在查整个出度顶点时,到边就截止了,不再进一步查边所在的顶点。
复杂的关系网络中,如果拆图拆的很细,就会导致管理成本很高,如属性列的对比更新操作很多。这可以采用一些自动化的,schema中管理上进一步编排,接下来把复杂的编排策略,通过schema表达出来,更新上去。这是精细化和自动化上的均衡。
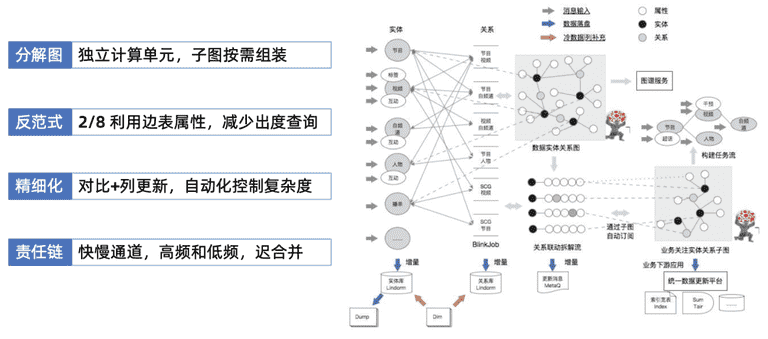
最后一点,我认为这是一个责任链,随着整个年轻化的发展,视频维护经常看到视频热度、vv播放次数,这些数据本身和视频更新频度不同,如果采用传统式一刀切 – 所有的都从原图开始订阅,订阅视频的vv、属性更新的过程中,导致下游反查链路的频度很高,这个过程中要把低频和高频拆开,最后一步进入子图阶段时,对数据做合并。算法的数据每天都向线上推,我们采用快-慢通道,新热的视频使用VIP通道、实现秒级更新到线上,算法日常数据,更新并不需要那么高频,使用慢的通道模式更新掉。这就是我们在系统实现中的经验,希望可以给大家一些参考。
来源
分享嘉宾:遨翔 阿里文娱 技术专家
编辑整理:Jane Zhang
出品平台:DataFunTalk