GGUF格式介绍
GGUF(GPT-Generated Unified Format)是推理框架llama.cpp 中使用的一种专为大语言模型设计的二进制文件格式,旨在实现模型的快速加载和保存,同时易于读取。GGUF格式的特点:
- 单文件部署:模型可以轻松分发和加载,不需要任何外部文件来提供额外信息。
- 可扩展性:可以在不破坏与现有模型的兼容性的情况下,向基于
GGML的执行器添加新功能或向GGUF模型添加新信息。 - mmap兼容性:可以使用
mmap加载模型,以实现快速加载和保存。 - 易于使用:可以使用少量代码轻松加载和保存模型,无论使用何种语言,无需外部库。
- 完整信息:加载模型所需的所有信息都包含在模型文件中,用户无需提供任何额外信息。
GGUF文件的结构如下图所示:

gguf
主要包括以下几个部分:
- 文件头(
Header):标识文件类型(GGUF)、版本号、张量数量。 - 元数据段(
Metadata):JSON-like键值对存储模型信息。 - 张量数据段(
Tensors):按量化类型存储模型权重。
它们使用general.alignment元数据字段中指定的全局对齐,如果需要,文件将用0x00字节填充到general.alignment的下一个倍数。除非另有说明,字段(包括数组)将按顺序连续写入,不进行对齐。模型默认为小端序,当然它们也可以是大端序以供大端序计算机使用,在这种情况下,所有值(包括元数据值和张量)也将是大端序。
GGUF命名约定
GGUF遵循<BaseName><SizeLabel><FineTune><Version><Encoding><Type><Shard>.gguf的命名约定,其中每个组件由-分隔(如果存在),这种命名方式的最终目的是为了让人们能够快速了解模型的关键信息。
每个组件的含义如下:
- BaseName:模型基础类型或架构的描述性名称。
- 可以从
gguf元数据general.basename派生,将空格替换为连字符。 - SizeLabel:参数权重类别(在排行榜中有用),表示为
<专家数量>x<数量><量级前缀>。 - 如果可用,可以从
gguf元数据general.size_label派生,如果缺失则进行计算。 - 支持带有单个字母量级前缀的十进制点的四舍五入,以帮助显示浮点指数,如下所示:
Q:千万亿参数。T:万亿参数。B:十亿参数。M:百万参数。K:千参数。
- 可以根据需要附加额外的
-<属性><数量><量级前缀>以指示其他感兴趣的属性。 - FineTune:模型微调目标的描述性名称(例如
Chat、Instruct等)。 - 可以从
gguf元数据general.finetune派生,将空格替换为连字符。 - Version:表示模型版本号,格式为
v<主版本>.<次版本>。 - 如果模型缺少版本号,则假设为
v1.0(首次公开发布)。 - 可以从
gguf元数据general.version派生。 - Encoding:指示应用于模型的权重编码方案。内容、类型混合和排列由用户代码决定,可以根据项目需求而有所不同。
- Type:指示
gguf文件的类型及其预期用途。 - 如果缺失,则文件默认为典型的
gguf张量模型文件。 LoRA:GGUF文件是LoRA适配器。vocab:仅包含词汇数据和元数据的GGUF文件。- Shard:(可选)指示模型已被拆分为多个分片,格式为
<分片编号>-of-<总分片数>。 - 分片编号:此模型中的分片位置。必须用零填充为
5位数字。
- 分片编号始终从
00001开始(例如,第一个分片总是从00001-of-XXXXX开始,而不是00000-of-XXXXX)。 - 总分片数:此模型中的总分片数。必须用零填充为
5位数字。
下面是对几个GGUF模型文件名的解释:
Mixtral-8x7B-v0.1-KQ2.gguf:- 模型名称:Mixtral
- 专家数量:8
- 参数数量:7B
- 版本号:v0.1
- 权重编码方案:KQ2
Hermes-2-Pro-Llama-3-8B-F16.gguf:- 模型名称:Hermes 2 Pro Llama 3
- 专家数量:0
- 参数数量:8B
- 版本号:v1.0
- 权重编码方案:F16
- 分片:不适用
Grok-100B-v1.0-Q4_0-00003-of-00009.gguf:- 模型名称:Grok
- 专家数量:0
- 参数数量:100B
- 版本号:v1.0
- 权重编码方案:Q4_0
- 分片:3 out of 9 total shards
GGUF命名规则约定所有模型文件都应该有基本名称、大小标签和版本,以便能够轻松验证其是否符合GGUF命名约定。例如,如果省略版本号,那么编码很容易被误认为是微调。
GGUF与其他格式对比
| 格式 | 特点 | 典型场景 |
|---|---|---|
| GGUF | 专为 CPU 推理优化,支持量化,元数据丰富 | 本地部署(llama.cpp) |
| PyTorch .pt | 原生训练格式,未量化,依赖 GPU 和 PyTorch 环境 | 模型训练/微调 |
| HuggingFace .safetensors | 安全序列化格式,未量化,需加载完整模型到内存 | 云端推理(GPU 加速) |
| ONNX | 跨框架通用格式,支持硬件加速,但量化功能有限 | 跨平台部署 |
GGUF格式转换
GGUF格式是推理框架llama.cpp使用的格式,但是通常模型是使用PyTorch之类的训练框架训练的,保存的格式一般使用HuggingFace的safetensors格式,因此使用llama.cpp进行推理之前需要把其他格式的模型转换为GGUF格式。
下面以DeepSeek R1的蒸馏模型DeepSeek-R1-Distill-Qwen-7B为例介绍如何将模型转换为GGUF格式。
首先从魔搭社区(或HuggingFace)下载模型:
pip install modelscope
modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local_dir DeepSeek-R1-Distill-Qwen-7B
下载好的模型是以safetensors格式存放的,可以调用llama.cpp的转换脚本把模型转换为GGUF格式:
# 安装python依赖库
pip install -r requirements.txt
# 转换模型
python convert_hf_to_gguf.py DeepSeek-R1-Distill-Qwen-7B/
转换成功后,在该目录下会生成一个FP16精度、GGUF格式的模型文件DeepSeek-R1-Distill-Qwen-7B-F16.gguf。
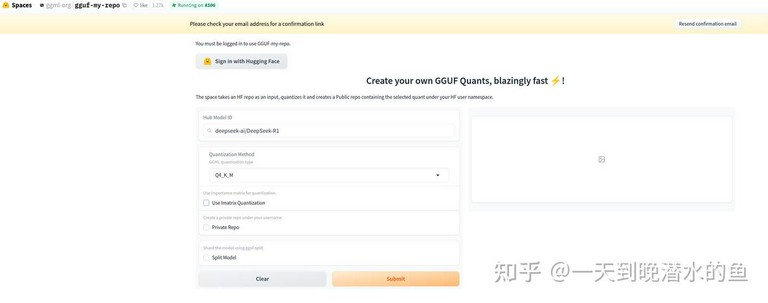
如果不想自己转模型,也可以在魔搭社区或HuggingFace上找带gguf后缀的模型,或者使用HuggingFace的gguf-my-repo进行转换,网址如下:
https://huggingface.co/spaces/ggml-org/gguf-my-repo
在该界面的Hub Modeil ID框中查找你想转的模型,然后Quantization Method中选择你想要的模型量化方式(关于GGUF模型的各种量化参数将在下文进行介绍),最后点击Submit就可以开始模型转换了。
GGUF量化参数介绍
llama.cpp的模型量化方法主要采用了分块量化(Block-wise Quantization)和K-Quantization算法来实现模型压缩与加速,其核心策略包括以下关键技术:
- 分块量化(Block-wise Quantization)
该方法将权重矩阵划分为固定大小的子块(如32或64元素为一组),每个子块独立进行量化。通过为每个子块分配独立的缩放因子(Scale)和零点(Zero Point),有效减少量化误差。例如,Q4_K_M表示每个权重用4比特存储,且子块内采用动态范围调整。 - K-Quantization(混合精度量化)
在子块内部进一步划分更小的单元(称为“超块”),根据数值分布动态选择量化参数。例如,Q4_K_M将超块拆分为多个子单元,每个子单元使用不同位数的缩放因子(如6bit的缩放因子和4bit的量化值),通过混合精度平衡精度与压缩率。 - 重要性矩阵(Imatrix)优化
通过分析模型推理过程中各层激活值的重要性,动态调整量化策略。高重要性区域保留更高精度(如FP16),低重要性区域采用激进量化(如Q2_K),从而在整体模型性能损失可控的前提下实现高效压缩。 - 量化类型分级策略
提供Q2_K至Q8_K等多种量化级别,其中字母后缀(如_M、_S)表示优化级别: - Q4_K_M:中等优化级别,平衡推理速度与精度(常用推荐)。
- Q5_K_S:轻量化级别,侧重减少内存占用
在GGUF的量化类型命名如 Q4_K_M中,Q4表示模型的主量化精度为4比特,K 和 M 分别代表量化过程中的分块策略(Block-wise Quantization)和混合精度优化级别。以下是详细解释:
K 的含义:分块量化(Block-wise Quantization) - 核心思想:将权重矩阵划分为多个小块(Block),对每个块单独进行量化,以降低整体误差。 - 技术细节: - 每个块(Block)的大小通常为32/64/128个权重值(具体数值由量化算法决定)。 - 块内共享量化参数(如缩放因子和零点),减少存储开销。 - 优势: - 相比全矩阵量化,分块量化能保留更多局部细节,降低信息损失。 - 提高量化后模型的生成质量和数学能力。
M 的含义:混合精度优化级别 GGUF在分块量化的基础上,进一步通过混合不同精度来提升效果,M 表示混合策略的强度等级为中等,另外还有S和L两个等级:
| 后缀 | 全称 | 说明 |
|---|---|---|
| S | Small/Simple | 轻度混合,仅对关键块使用更高精度(如 6-bit),其他块用低精度(如 4-bit) |
| M | Medium | 中等混合,更多块使用高精度,平衡速度和精度(推荐默认选择) |
| L | Large | 高度混合,最大化高精度块比例,接近原始模型精度(速度最慢) |
以下是关于 GGUF 量化方法选择策略的详细解析,包含不同场景下的量化建议和性能对比:
GGUF量化方法分类与特性
| 量化类型 | 比特数 | 内存占用(以7B模型为例) | 推理速度 | 精度保持 | 适用场景 |
|---|---|---|---|---|---|
| Q2_K | 2-bit | ~2.8GB | 最快 | 低 | 极低资源设备(手机) |
| Q3_K_M | 3-bit | ~3.3GB | 快 | 中低 | 快速测试/简单问答 |
| Q4_0 | 4-bit | ~3.8GB | 快 | 中等 | 平衡型通用场景 |
| Q4_K_M | 4-bit | ~4.0GB | 中等 | 中高 | 推荐默认选择 |
| Q5_0 | 5-bit | ~4.5GB | 中等 | 高 | 复杂任务(代码生成) |
| Q5_K_M | 5-bit | ~4.7GB | 中等 | 很高 | 高质量生成(推荐首选) |
| Q6_K | 6-bit | ~5.5GB | 较慢 | 接近原始 | 学术研究/最小精度损失 |
| Q8_0 | 8-bit | ~7.0GB | 最慢 | 无损 | 基准测试/对比实验 |
选择建议
- 优先选择
_K_M后缀:在相同比特数下,质量和速度平衡最佳。 - 极端资源场景:可用
_K_S牺牲少量质量换取更快速度。 - 研究用途:使用
_K_L或非混合量化(如Q6_K)作为基准。
按硬件资源选择: - 手机/嵌入式设备: - 首选 Q4_0 或 Q3_K_M(内存 <4GB) - 示例:在 iPhone 14 上运行 Q4_K_M 的 7B 模型,推理速度约 20 tokens/s - 低配 PC(8GB 内存): - 选择 Q4_K_M 或 Q5_K_M(7B 模型占用约4-5GB) - 高性能 CPU(服务器/工作站): - 使用 Q5_K_M 或 Q6_K 以获得最佳质量
只要理解了 K 和 M 的含义,我们就可以更精准地根据硬件和任务类型选择合适的量化模型了。