1. 图状结构数据广泛存在
字节跳动的所有产品的大部分业务数据,几乎都可以归入到以下三种:
- 用户信息、用户和用户的关系(关注、好友等);
- 内容(视频、文章、广告等);
- 用户和内容的联系(点赞、评论、转发、点击广告等)。
这三种数据关联在一起,形成图状(Graph)结构数据。
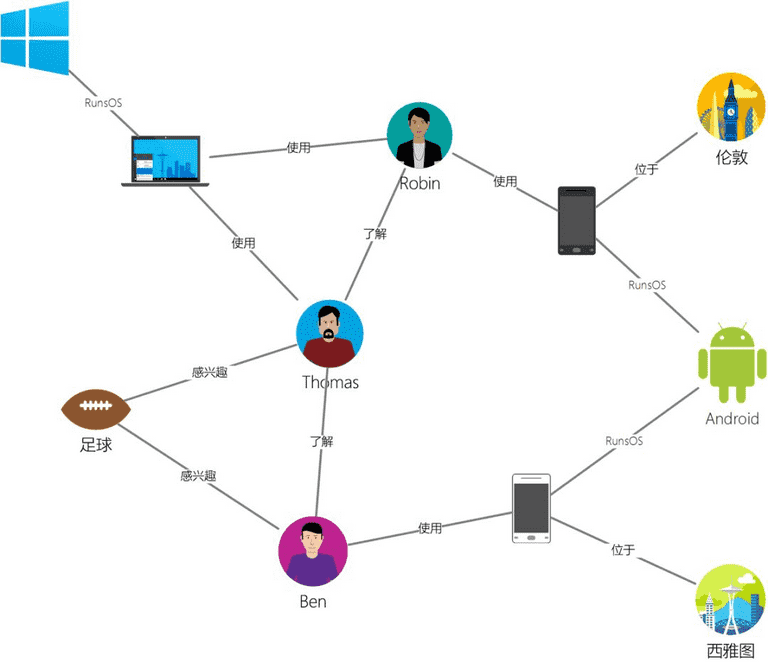
为了满足 social graph 的在线增删改查场景,字节跳动自研了分布式图存储系统——ByteGraph。针对上述图状结构数据,ByteGraph 支持有向属性图数据模型,支持 Gremlin 查询语言,支持灵活丰富的写入和查询接口,读写吞吐可扩展到千万 QPS,延迟毫秒级。目前,ByteGraph 支持了头条、抖音、 TikTok、西瓜、火山等几乎字节跳动全部产品线,遍布全球机房。在这篇文章中,将从适用场景、内部架构、关键问题分析几个方面作深入介绍。
ByteGraph 主要用于在线 OLTP 场景,而在离线场景下,图数据的分析和计算需求也逐渐显现。2019 年年初,Gartner 数据与分析峰会上将图列为 2019 年十大数据和分析趋势之一,预计全球图分析应用将以每年 100% 的速度迅猛增长,2020 年将达到 80 亿美元。因此,我们团队同时也开启了在离线图计算场景的支持和实践。
下面会从图数据库和图计算两个部分,分别来介绍字节跳动在这方面的一些工作。
2. 自研图数据库(ByteGraph)介绍
从数据模型角度看,图数据库内部数据是有向属性图,其基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性;作为一个工具,图数据对外提供的接口都是围绕这些元素展开。
图数据库本质也是一个存储系统,它和常见的 KV 存储系统、MySQL 存储系统的相比主要区别在于目标数据的逻辑关系不同和访问模式不同,对于数据内在关系是图模型以及在图上游走类和模式匹配类的查询,比如社交关系查询,图数据库会有更大的性能优势和更加简洁高效的接口。
2.1 为什么不选择开源图数据库
图数据库在 90 年代出现,直到最近几年在数据爆炸的大趋势下快速发展,百花齐放;但目前比较成熟的大部分都是面对传统行业较小的数据集和较低的访问吞吐场景,比如开源的 Neo4j 是单机架构;因此,在互联网场景下,通常都是基于已有的基础设施定制系统:比如 Facebook 基于 MySQL 系统封装了 Social Graph 系统 TAO,几乎承载了 Facebook 所有数据逻辑;Linkedln 在 KV 之上构建了 Social Graph 服务;微博是基于 Redis 构建了粉丝和关注关系。
字节跳动的 Graph 在线存储场景, 其需求也是有自身特点的,可以总结为:
- 海量数据存储:百亿点、万亿边的数据规模;并且图符合幂律分布,比如少量大 V 粉丝达到几千万;
- 海量吞吐:最大集群 QPS 达到数千万;
- 低延迟:要求访问延迟 pct99 需要限制在毫秒级;
- 读多写少:读流量是写流量的接近百倍之多;
- 轻量查询多,重量查询少:90%查询是图上二度以内查询;
- 容灾架构演进:要能支持字节跳动城域网、广域网、洲际网络之间主备容灾、异地多活等不同容灾部署方案。
事实上,我们调研过了很多业界系统, 这个主题可以再单独分享一篇文章。但是,面对字节跳动世界级的海量数据和海量并发请求,用万亿级分布式存储、千万高并发、低延迟、稳定可控这三个条件一起去筛选,业界在线上被验证稳定可信赖的开源图存储系统基本没有满足的了;另外,对于一个承载公司核心数据的重要的基础设施,是值得长期投入并且深度掌控的。
因此,我们在 18 年 8 月份,开始从第一行代码开始踏上图数据库的漫漫征程,从解决一个最核心的抖音社交关系问题入手,逐渐演变为支持有向属性图数据模型、支持写入原子性、部分 Gremlin 图查询语言的通用图数据库系统,在公司所有产品体系落地,我们称之为 ByteGraph。下面,会从数据模型、系统架构等几个部分,由浅入深和大家分享我们的工作。
2.2 ByteGraph 的数据模型和 API
数据模型
就像我们在使用 SQL 数据库时,先要完成数据库 Schema 以及范式设计一样,ByteGraph 也需要用户完成类似的数据模型抽象,但图的数据抽象更加简单,基本上是把数据之间的关系“翻译”成有向属性图,我们称之为“构图”过程。
比如在前面提到的,如果想把用户关系存入 ByteGraph,第一步就是需要把用户抽象为点,第二步把”关注关系”、“好友关系”抽象为边就完全搞定了。下面,我们就从代码层面介绍下点边的数据类型。
- 点(Vertex)
点是图数据库的基本元素,通常反映的是静态信息。在 ByteGraph 中,点包含以下字段:
- 点的id(uint64_t): 比如用户id作为一个点
- 点的type(uint32_t): 比如appID作为点的type
- 点的属性(KV 对):比如 'name': string,'age': int, 'gender': male,等自定义属性
- [id, type]唯一定义一个点
- 边(Edge)
一条边由两个点和点之间的边的类型组成,边可以描述点之间的关系,比如用户 A 关注了用户 B ,可以用以下字段来描述:
- 两个点(Vertex): 比如用户A和用户B
- 边的类型(string): 比如“关注”
- 边的时间戳(uint64_t):这个t值是业务自定义含义的,比如可以用于记录关注发生的时间戳
- 边属性(KV对):比如'ts_us': int64 描述关系创建时间的属性,以及其他用户自定义属性
- 边的方向
在 ByteGraph 的数据模型中,边是有方向的,目前支持 3 种边的方向:
- 正向边:如 A 关注 B(A -> B)
- 反向边:如 B 被 A 关注(B <- A)
- 双向边:如 A 与 B 是好友(A <-> B)
场景使用伪码举例
构图完毕后,我们就可以把业务逻辑通过 Gremlin 查询语言来实现了;为便于大家理解,我们列举几种典型的场景为例。
- 场景一:记录关注关系 A 关注 B
// 创建用户A和B,可以使用 .property('name', 'Alice') 语句添加用户属性
g.addV().property("type", A.type).property("id", A.id)
g.addV().property("type", B.type).property("id", B.id)
// 创建关注关系 A -> B,其中addE("关注")中指定了边的类型信息,from和to分别指定起点和终点,
g.addE("关注").from(A.id, A.type).to(B.id, B.type).property("ts_us", now)
- 场景二:查询 A 关注的且关注了 C 的所有用户
用户 A 进入用户 C 的详情页面,想看看 A 和 C 之间的二度中间节点有哪些,比如 A->B,B->C,B 则为中间节点。
// where()表示对于上一个step的每个执行结果,执行子查询过滤条件,只保留关注了C的用户。
g.V().has("type", A.type).has("id", A.id).out("关注").where(out("关注").has("type", C.type).has("id", C.id).count().is(gte(1)))
- 场景三:查询 A 的好友的好友(二度关系)
// both("好友")相当于in("好友")和out("好友")的合集
g.V().has("type", A.type).has("id", A.id).both("好友").both("好友").toSet()
2.3 系统架构
前面几个章节,从用户角度介绍了 ByteGraph 的适用场景和对外使用姿势。那 ByteGraph 架构是怎样的,内部是如何工作的呢,这一节就来从内部实现来作进一步介绍。
下面这张图展示了 ByteGraph 的内部架构,其中 bg 是 ByteGraph 的缩写。
就像 MySQL 通常可以分为 SQL 层和引擎层两层一样,ByteGraph 自上而下分为查询层 (bgdb)、存储/事务引擎层(bgkv)、磁盘存储层三层,每层都是由多个进程实例组成。其中 bgdb 层与 bgkv 层混合部署,磁盘存储层独立部署,我们详细介绍每一层的关键设计。
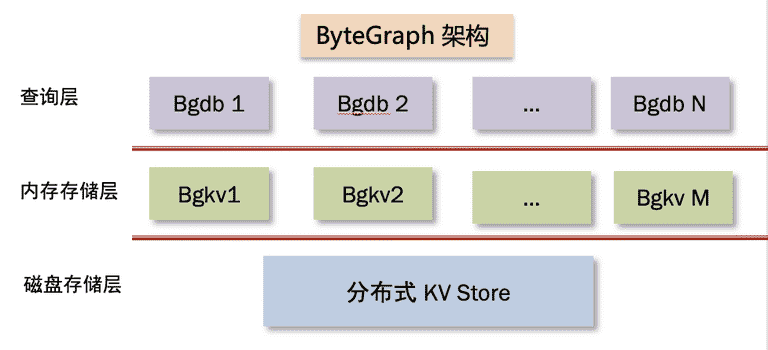
查询层(bgdb)
bgdb 层和 MySQL 的 SQL 层一样,主要工作是做读写请求的解析和处理;其中,所谓“处理”可以分为以下三个步骤:
- 将客户端发来的 Gremlin 查询语句做语法解析,生成执行计划;
- 并根据一定的路由规则(例如一致性哈希)找到目标数据所在的存储节点(bgkv),将执行计划中的读写请求发送给 多个 bgkv;
- 将 bgkv 读写结果汇总以及过滤处理,得到最终结果,返回给客户端。
bgdb 层没有状态,可以水平扩容,用 Go 语言开发。
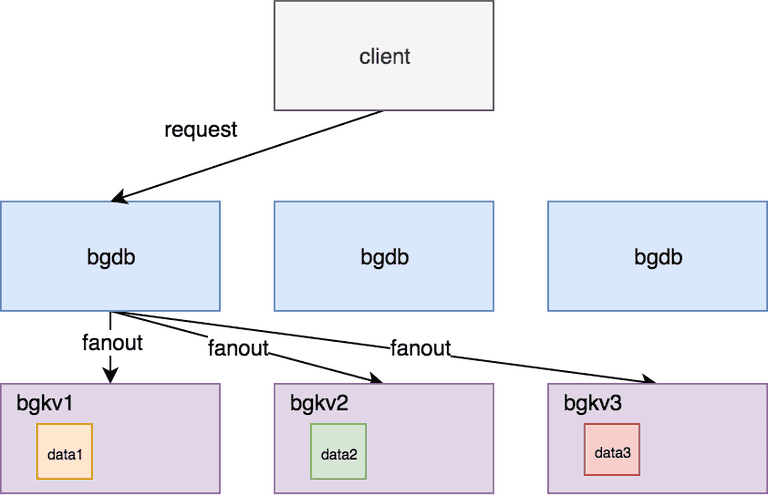
存储/事务引擎层(bgkv)
bgkv 层是由多个进程实例组成,每个实例管理整个集群数据的一个子集(shard / partition)。
bgkv 层的实现和功能有点类似内存数据库,提供高性能的数据读写功能,其特点是:
- 接口不同:只提供点边读写接口;
- 支持算子下推:通过把计算(算子)移动到存储(bgkv)上,能够有效提升读性能; (举例:比如某个大 V 最近一年一直在涨粉,bgkv 支持查询最近的 100 个粉丝,则不必读出所有的百万粉丝。)
- 缓存存储有机结合:其作为 KV store 的缓存层,提供缓存管理的功能,支持缓存加载、换出、缓存和磁盘同步异步 sync 等复杂功能。
从上述描述可以看出,bgkv 的性能和内存使用效率是非常关键的,因此采用 C++ 编写。
磁盘存储层(KV Cluster)
为了能够提供海量存储空间和较高的可靠性、可用性,数据必须最终落入磁盘,我们底层存储是选择了公司自研的分布式 KV store。
如何把图存储在 KV 数据库中
上一小节,只是介绍了 ByteGraph 内部三层的关系,细心的读者可能已经发现,ByteGraph 外部是图接口,底层是依赖 KV 存储,那么问题来了:如何把动辄百万粉丝的图数据存储在一个 KV 系统上呢?
在字节跳动的业务场景中,存在很多访问热度和“数据密度”极高的场景,比如抖音的大 V、热门的文章等,其粉丝数或者点赞数会超过千万级别;但作为 KV store,希望业务方的 KV 对的大小(Byte 数)是控制在 KB 量级的,且最好是大小均匀的:对于太大的 value,是会瞬间打满 I/O 路径的,无法保证线上稳定性;对于特别小的 value,则存储效率比较低。事实上,数据大小不均匀这个问题困扰了很多业务团队,在线上也会经常爆出事故。
对于一个有千万粉丝的抖音大 V,相当于图中的某个点有千万条边的出度,不仅要能存储下来,而且要能满足线上毫秒级的增删查改,那么 ByteGraph 是如何解决这个问题的呢?
思路其实很简单,总结来说,就是采用灵活的边聚合方式,使得 KV store 中的 value 大小是均匀的,具体可以用以下四条来描述:
- 一个点(Vertex)和其所有相连的边组成了一数据组(Group);不同的起点和及其终点是属于不同的 Group,是存储在不同的 KV 对的;比如用户 A 的粉丝和用户 B 的粉丝,就是分成不同 KV 存储;
- 对于某一个点的及其出边,当出度数量比较小(KB 级别),将其所有出度即所有终点序列化为一个 KV 对,我们称之为一级存储方式(后面会展开描述);
- 当一个点的出度逐渐增多,比如一个普通用户逐渐成长为抖音大 V,我们则采用分布式 B-Tree 组织这百万粉丝,我们称之为二级存储;
- 一级存储和二级存储之间可以在线并发安全的互相切换;
- 一级存储格式
一级存储格式中,只有一个 KV 对,key 和 value 的编码:
- key: 某个起点 id + 起点 type + 边 type
- value: 此起点的所有出边(Edge)及其边上属性聚合作为 value,但不包括终点的属性
- 二级存储(点的出度大于阈值)
如果一个大 V 疯狂涨粉,则存储粉丝的 value 就会越来越大,解决这个问题的思路也很朴素:拆成多个 KV 对。
但如何拆呢?ByteGraph 的方式就是把所有出度和终点拆成多个 KV 对,所有 KV 对形成一棵逻辑上的分布式 B-Tree,之所以说“逻辑上的”,是因为树中的节点关系是靠 KV 中 key 来指向的,并非内存指针;B-Tree 是分布式的,是指构成这棵树的各级节点是分布在集群多个实例上的,并不是单机索引关系。具体关系如下图所示:
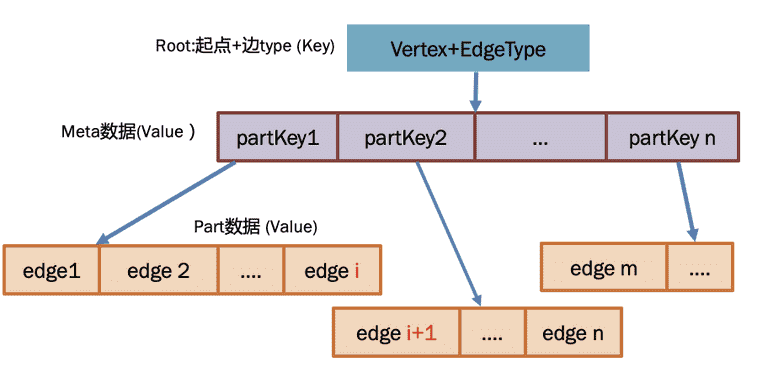
其中,整棵 B-Tree 由多组 KV 对组成,按照关系可以分为三种数据:
- 根节点:根节点本质是一个 KV 系统中的一个 key,其编码方式和一级存储中的 key 相同
- Meta 数据:
- Meta 数据本质是一个 KV 中的 value,和根节点组成了 KV 对;
- Meta 内部存储了多个 PartKey,其中每个 PartKey 都是一个 KV 对中的 key,其对应的 value 数据就是下面介绍的 Part 数据;
- Part 数据
- 对于二级存储格式,存在多个 Part,每个 Part 存储部分出边的属性和终点 ID
- 每个 Part 都是一个 KV 对的 value,其对应的 key 存储在 Meta 中。
从上述描述可以看出,对于一个出度很多的点和其边的数据(比如大 V 和其粉丝),在 ByteGraph 中,是存储为多个 KV 的,面对增删查改的需求,都需要在 B-Tree 上做二分查找。相比于一条边一个 KV 对或者所有边存储成一个 KV 对的方式,B-Tree 的组织方式能够有效的在读放大和写放大之间做一些动态调整。
但在实际业务场景下,粉丝会处于动态变化之中:新诞生的大 V 会快速新增粉丝,有些大 V 会持续掉粉;因此,存储方式会在一级存储和二级存储之间转换,并且 B-Tree 会持续的分裂或者合并;这就会引发分布式的并发增删查改以及分裂合并等复杂的问题,有机会可以再单独分享下这个有趣的设计。
ByteGraph 和 KV store 的关系,类似文件系统和块设备的关系,块设备负责将存储资源池化并提供 Low Level 的读写接口,文件系统在块设备上把元数据和数据组织成各种树的索引结构,并封装丰富的 POSIX 接口,便于外部使用。
2.4 一些问题深入探讨
第三节介绍了 ByteGraph 的内在架构,现在我们更进一步,来看看一个分布式存储系统,在面对字节跳动万亿数据上亿并发的业务场景下两个问题的分析。
热点数据读写解决
热点数据在字节跳动的线上业务中广泛存在:热点视频、热点文章、大 V 用户、热点广告等等;热点数据可能会出现瞬时出现大量读写。ByteGraph 在线上业务的实践中,打磨出一整套应对性方案。
- 热点读
热点读的场景随处可见,比如线上实际场景:某个热点视频被频繁刷新,查看点赞数量等。在这种场景下,意味着访问有很强的数据局部性,缓存命中率会很高,因此,我们设计实现了多级的 Query Cache 机制以及热点请求转发机制;在 bgdb 查询层缓存查询结果, bgdb 单节点缓存命中读性能 20w QPS 以上,而且多个 bgdb 可以并发处理同一个热点的读请求,则系统整体应对热点度的“弹性”是非常充足的。
- 热点写
热点读和热点写通常是相伴而生的,热点写的例子也是随处可见,比如:热点新闻被疯狂转发, 热点视频被疯狂点赞等等。对于数据库而言,热点写入导致的性能退化的背后原因通常有两个:行锁冲突高或者磁盘写入 IOPS 被打满,我们分别来分析:
- 行锁冲突高:目前 ByteGraph 是单行事务模型,只有内存结构锁,这个锁的并发量是每秒千万级,基本不会构成写入瓶颈;
- 磁盘 IOPS 被打满:
- IOPS(I/O Count Per Second)的概念:磁盘每秒的写入请求数量是有上限的,不同型号的固态硬盘的 IOPS 各异,但都有一个上限,当上游写入流量超过这个阈值时候,请求就会排队,造成整个数据通路堵塞,延迟就会呈现指数上涨最终服务变成不可用。
- Group Commit 解决方案:Group Commit 是数据库中的一个成熟的技术方案,简单来讲,就是多个写请求在 bgkv 内存中汇聚起来,聚成一个 Batch 写入 KV store,则对外体现的写入速率就是 BatchSize * IOPS。
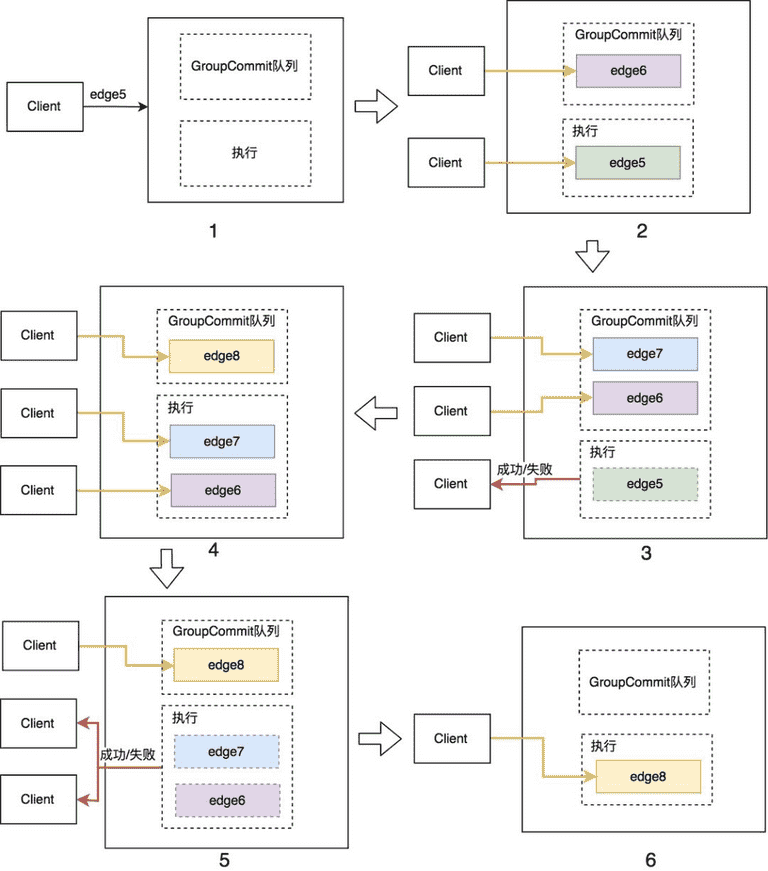
对于某个独立数据源来说,一般热点写的请求比热点读会少很多,一般不会超过 10K QPS,目前 ByteGraph 线上还没有出现过热点写问题问题。
图的索引
就像关系型数据库一样,图数据库也可以构建索引。默认情况下,对于同一个起点,我们会采用边上的属性(时间戳)作为主键索引;但为了加速查询,我们也支持其他元素(终点、其他属性)来构建二级的聚簇索引,这样很多查找就从全部遍历优化成了二分查找,使得查询速度大幅提升。
ByteGraph 默认按照边上的时间戳(ts)来排序存储,因此对于以下请求,查询效率很高:
- 查询最近的若干个点赞
- 查询某个指定时间范围窗口内加的好友
方向的索引可能有些费解,举个例子说明下:给定两个用户来查询是否存在粉丝关系,其中一个用户是大 V,另一个是普通用户,大 V 的粉丝可达千万,但普通用户的关注者一般不会很多;因此,如果用普通用户作为起点大 V 作为终点,查询代价就会低很多。其实,很多场景下,我们还需要用户能够根据任意一个属性来构建索引,这个也是我们正在支持的重要功能之一。
2.5 未来探索
过去的一年半时间里,ByteGraph 都是在有限的人力情况下,优先满足业务需求,在系统能力构建方面还是有些薄弱的,有大量问题都需要在未来突破解决:
- 从图存储到图数据库:对于一个数据库系统,是否支持 ACID 的事务,是一个核心问题,目前 ByteGraph 只解决了原子性和一致性,对于最复杂的隔离性还完全没有触碰,这是一个非常复杂的问题;另外,中国信通院发布了国内图数据库功能白皮书,以此标准,如果想做好一个功能完备的“数据库”系统,我们面对的还是星辰大海;
- 标准的图查询语言:目前,图数据库的查询语言业界还未形成标准(GQL 即将在 2020 年发布),ByteGraph 选择 Apache、AWS 、阿里云的 Gremlin 语言体系,但目前也只是支持了一个子集,更多的语法支持、更深入的查询优化还未开展;
- Cloud Native 存储架构演进:现在 ByteGraph 还是构建与 KV 存储之上,独占物理机全部资源;从资源弹性部署、运维托管等角度是否有其他架构演进的探索可能,从查询到事务再到磁盘存储是否有深度垂直整合优化的空间,也是一个没有被回答的问题;
- 现在 ByteGraph 是在 OLTP 场景下承载了大量线上数据,这些数据同时也会应用到推荐、风控等复杂分析和图计算场景,如何把 TP 和轻量 AP 查询融合在一起,具备部分 HTAP 能力,也是一个空间广阔的蓝海领域。
3. 图计算系统介绍与实践
3.1 图计算技术背景
图计算简介
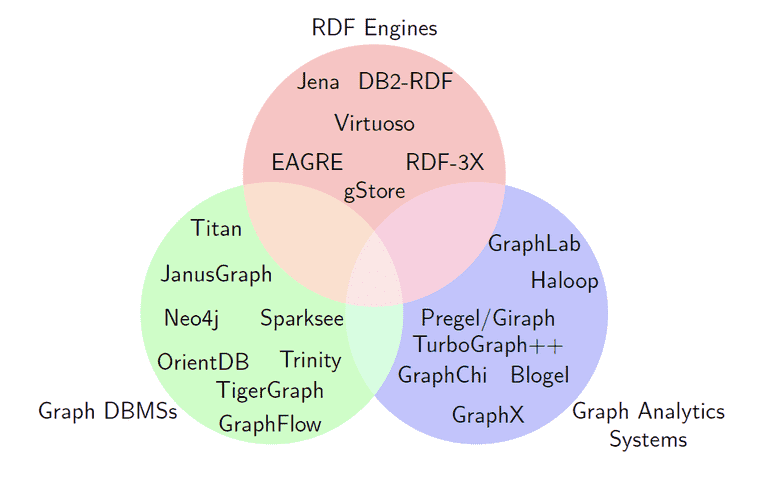
图数据库重点面对 OLTP 场景,以事务为核心,强调增删查改并重,并且一个查询往往只是涉及到图中的少量数据;而图计算与之不同,是解决大规模图数据处理的方法,面对 OLAP 场景,是对整个图做分析计算,下图(引用自 VLDB 2019 keynote 《Graph Processing: A Panaromic View and Some Open Problems》)描述了图计算和图数据库的一些领域区分。
举个图计算的简单例子,在我们比较熟悉的 Google 的搜索场景中,需要基于网页链接关系计算每个网页的 PageRank 值,用来对网页进行排序。网页链接关系其实就是一张图,而基于网页链接关系的 PageRank 计算,其实就是在这张图上运行图算法,也就是图计算。
对于小规模的图,我们可以用单机来进行计算。但随着数据量的增大,一般需要引入分布式的计算系统来解决,并且要能够高效地运行各种类型的图算法。
批处理系统
大规模数据处理我们直接想到的就是使用 MapReduce / Spark 等批处理系统,字节跳动在初期也有不少业务使用 MapReduce / Spark 来实现图算法。得益于批处理系统的广泛使用,业务同学能够快速实现并上线自己的算法逻辑。
批处理系统本身是为了处理行式数据而设计的,其能够轻易地将工作负载分散在不同的机器上,并行地处理大量的数据。不过图数据比较特殊,天然具有关联性,无法像行式数据一样直接切割。如果用批处理系统来运行图算法,就可能会引入大量的 Shuffle 来实现关系的连接,而 Shuffle 是一项很重的操作,不仅会导致任务运行时间长,并且会浪费很多计算资源。
图计算系统
图计算系统是针对图算法的特点而衍生出的专用计算设施,能够高效地运行图算法。因此随着业务的发展,我们迫切需要引入图计算系统来解决图数据处理的问题。图计算也是比较成熟的领域,在学术界和工业界已有大量的系统,这些系统在不同场景,也各有优劣势。
由于面向不同的数据特征、不同的算法特性等,图计算系统在平台架构、计算模型、图划分、执行模型、通信模型等方面各有取舍。下面,我们从不同角度对图计算的一些现有技术做些分类分析。
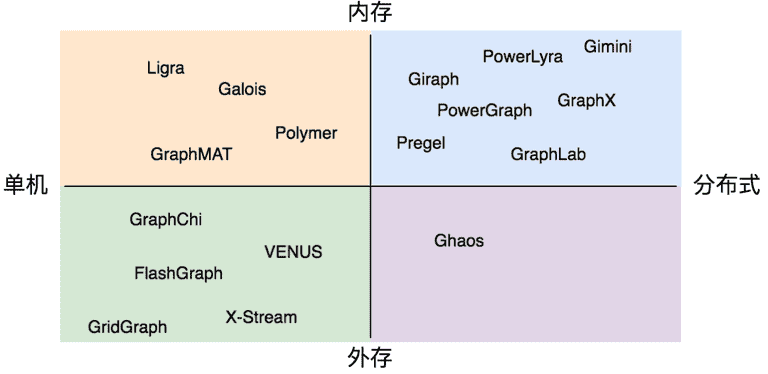
- 分布架构
按照分布架构,图计算可以分为单机或分布式、全内存或使用外存几种,常见的各种图计算系统如下图所示。单机架构的优势在于无需考虑分布式的通信开销,但通常难以快速处理大规模的图数据;分布式则通过通信或分布式共享内存将可处理的数据规模扩大,但通常也会引入巨大的额外开销。
- 计算模型
按照计算对象,图数据计算模型可以分为节点中心计算模型、边中心计算模型、子图中心计算模型等。
大部分图计算系统都采用了节点中心计算模型(这里的节点指图上的一个点),该模型来自 Google 的 Pregel,核心思想是用户编程过程中,以图中一个节点及其邻边作为输入来进行运算,具有编程简单的优势。典型的节点中心计算模型包括 Pregel 提出的 Pregel API 、 PowerGraph 提出的 GAS API 以及其他一些 API。
Pregel 创新性地提出了 “think like a vertex” 的思想,用户只需编写处理一个节点的逻辑,即可被拓展到整张图进行迭代运算,使用 Pregel 描述的 PageRank 如下图所示:
def pagerank(vertex_id, msgs):
// 计算收到消息的值之和
msg_sum = sum(msgs)
// 更新当前PR值
pr = 0.15 + 0.85 * msg_sum
// 用新计算的PR值发送消息
for nr in out_neighbor(vertex_id):
msg = pr / out_degree(vertex_id)
send_msg(nr, msg)
// 检查是否收敛
if converged(pr):
vote_halt(vertex_id)
GAS API 则是 PowerGraph 为了解决幂律图(一小部分节点的度数非常高)的问题,将对一个节点的处理逻辑,拆分为了 Gather、Apply、Scatter 三阶段。在计算满足交换律和结合律的情况下,通过使用 GAS 模型,通信成本从 |E| 降低到了 |V|,使用 GAS 描述的 PageRank 如下图所示:
def gather(msg_a, msg_b):
// 汇聚消息
return msg_a + msg_b
def apply(vertex_id, msg_sum):
// 更新PR值
pr = 0.15 + 0.85 * msg_sum
// 判断是否收敛
if converged(pr):
vote_halt(vertex_id)
def scatter(vertex_id, nr):
// 发送消息
return pr / out_degree(vertex_id)
- 图划分
对于单机无法处理的超级大图,则需要将图数据划分成几个子图,采用分布式计算方式,因此,会涉及到图划分的问题,即如何将一整张图切割成子图,并分配给不同的机器进行分布式地计算。常见的图划分方式有切边法(Edge-Cut)和切点法(Vertex-Cut),其示意图如下所示:
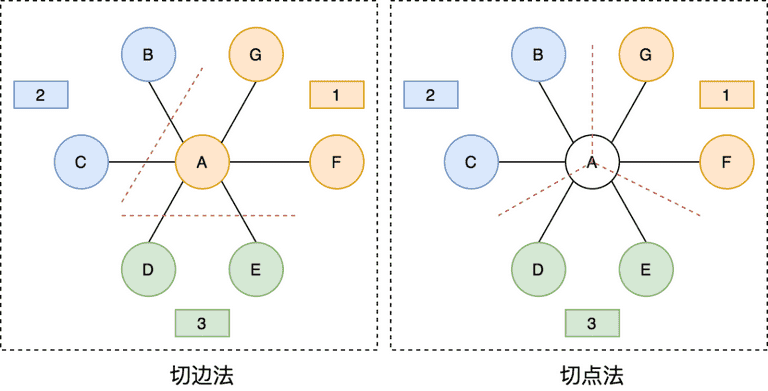
切边法顾名思义,会从一条边中间切开,两边的节点会分布在不同的图分区,每个节点全局只会出现一次,但切边法可能会导致一条边在全局出现两次。如上左图所示,节点 A 与节点 B 之间有一条边,切边法会在 A 和 B 中间切开,A 属于图分区 1,B 属于图分区 2。
切点法则是将一个节点切开,该节点上不同的边会分布在不同的图分区,每条边全局只会出现一次,但切点法会导致一个节点在全局出现多次。如上图右图所示,节点 A 被切分为 3 份,其中边 AB 属于分区 2,边 AD 属于图分区 3。
图划分还会涉及到分图策略,比如切点法会有各种策略的切法:按边随机哈希、Edge1D、Edge2D 等等。有些策略是可全局并行执行分图的,速度快,但负载均衡和计算时的通信效率不理想;有些是需要串行执行的但负载均衡、通信效率会更好,各种策略需要根据不同的业务场景进行选择。
- 执行模型
执行模型解决的是不同的节点在迭代过程中,如何协调迭代进度的问题。图计算通常是全图多轮迭代的计算,比如 PageRank 算法,需要持续迭代直至全图所有节点收敛才会结束。
在图划分完成后,每个子图会被分配到对应的机器进行处理,由于不同机器间运算环境、计算负载的不同,不同机器的运算速度是不同的,导致图上不同节点间的迭代速度也是不同的。为了应对不同节点间迭代速度的不同,有同步计算、异步计算、以及半同步计算三种执行模型。
同步计算是全图所有节点完成一轮迭代之后,才开启下一轮迭代,因为通常每个节点都会依赖其他节点在上一轮迭代产生的结果,因此同步计算的结果是正确的。
异步计算则是每个节点不等待其他节点的迭代进度,在自己计算完一轮迭代后直接开启下一轮迭代,所以就会导致很多节点还没有完全拿到上一轮的结果就开始了下一轮计算。
半同步计算是两者的综合,其思想是允许一定的不同步,但当计算最快的节点与计算最慢的节点相差一定迭代轮数时,最快的节点会进行等待。同步计算和异步计算的示意图如下图:
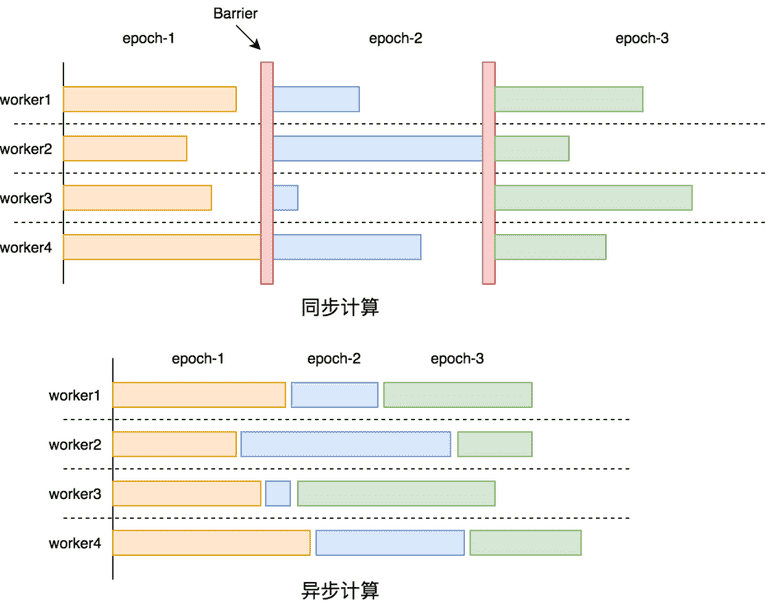
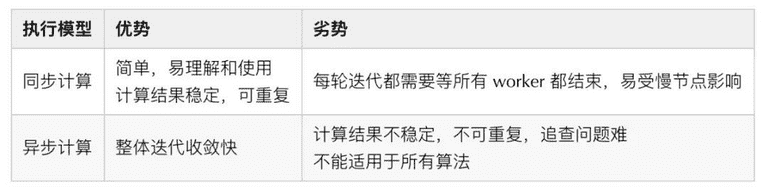
同步计算和异步计算各有优劣,其对比如下表所示,半同步是两者折中。多数图计算系统都采用了同步计算模型,虽然计算效率比异步计算弱一些,但它具有易于理解、计算稳定、结果准确、可解释性强等多个重要的优点。
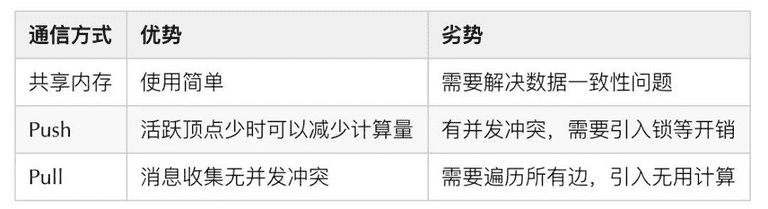
- 通信模型
为了实现拓展性,图计算采用了不同的通信模型,大致可分为分布式共享内存、Push 以及 Pull。分布式共享内存将数据存储在共享内存中,通过直接操作共享内存完成信息交互;Push 模型是沿着出边方向主动推送消息;Pull 则是沿着入边方向主动收消息。三者优劣对比如下表格所示:
3.2 技术选型
由于字节跳动要处理的是世界级的超大规模图,同时还对计算任务运行时长有要求,因此主要考虑高性能、可拓展性强的图计算系统。工业界使用比较多的系统主要有以下几类:
Pregel & Giraph
Google 提出了 Pregel 来解决图算法在 MapReduce 上运行低效的问题,但没有开源。Facebook 根据 Pregel 的思路发展了开源系统 Giraph,但 Giraph 有两个问题:一是 Giraph 的社区不是很活跃;二是现实生活中的图都是符合幂律分布的图,即有一小部分点的边数非常多,这些点在 Pregel 的计算模式下很容易拖慢整个计算任务。
GraphX
GraphX 是基于 Spark 构建的图计算系统,融合了很多 PowerGraph 的思想,并对 Spark 在运行图算法过程中的多余 Shuffle 进行了优化。GraphX 对比原生 Spark 在性能方面有很大优势,但 GraphX 非常费内存,Shuffle 效率也不是很高,导致运行时间也比较长。
Gemini
Gemini 是 16 年发表再在 OSDI 的一篇图计算系统论文,结合了多种图计算系统的优势,并且有开源实现,作为最快的图计算引擎之一,得到了业界的普遍认可。
正如《Scalability! But at what COST? 》一文指出,多数的图计算系统为了拓展性,忽视了单机的性能,加之分布式带来的巨大通信开销,导致多机环境下的计算性能有时甚至反而不如单机环境。针对这些问题,Gemini 的做了针对性优化设计,简单总结为:
- 图存储格式优化内存开销:采用 CSC 和 CSR 的方式存储图,并对 CSC/CSR 进一步建立索引降低内存占用;
- Hierarchical Chunk-Based Partitioning:通过在 Node、Numa、Socket 多个维度做区域感知的图切分,减少通信开销;
- 自适应的 Push / Pull 计算:采用了双模式通信策略,能根据当前活跃节点的数量动态地切换到稠密或稀疏模式。
兼顾单机性能和扩展性,使得 Gemini 处于图计算性能最前沿,同时,Gemini 团队也成立了商业公司专注图数据的处理。
3.3 基于开源的实践
Tencent Plato 是基于 Gemini 思想的开源图计算系统,采用了 Gemini 的核心设计思路,但相比 Gemini 的开源版本有更加完善的工程实现,我们基于此,做了大量重构和二次开发,将其应用到生成环境中,这里分享下我们的实践。
更大数据规模的探索
开源实现中有个非常关键的假设:一张图中的点的数量不能超过 40 亿个;但字节跳动部分业务场景的数据规模远超出了这个数额。为了支持千亿万亿点的规模,我们将产生内存瓶颈的单机处理模块,重构为分布式实现。
- 点 ID 的编码
Gemini 的一个重要创新就是提出了基于 Chunk 的图分区方法。这种图分区方法需要将点 id 从 0 开始连续递增编码,但输入的图数据中,点 id 是随机生成的,因此需要对点 id 进行一次映射,保证其连续递增。具体实现方法是,在计算任务开始之前将原始的业务 id 转换为从零开始的递增 id,计算结束后再将 id 映射回去,如下图所示:
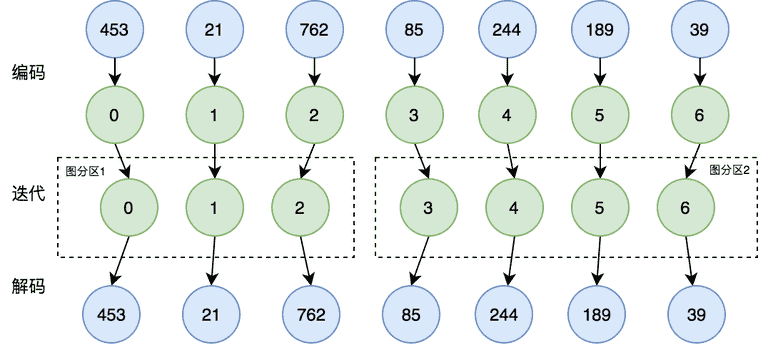
在开源实现中,是假设图中点的数量不可超过 40 亿,40 亿的 id 数据是可以存储在单机内存中,因此采用比较简单的实现方式:分布式计算集群中的每台机器冗余存储了所有点 id 的映射关系。然而,当点的数量从 40 亿到千亿级别,每台机器仅 id 映射表就需要数百 GB 的内存,单机存储方案就变得不再可行,因此需要将映射表分成 shard 分布式地存储,具体实现方式如下:
我们通过哈希将原始业务点 id 打散在不同的机器,并行地分配全局从 0 开始连续递增的 id。生成 id 映射关系后,每台机器都会存有 id 映射表的一部分。随后再将边数据分别按起点和终点哈希,发送到对应的机器进行编码,最终得到的数据即为可用于计算的数据。当计算运行结束后,需要数据需要映射回业务 id,其过程和上述也是类似的。
上面描述的仅仅是图编码部分,40 亿点的值域限制还广泛存在于构图和实际计算过程中,我们都对此做了重构。另外在我们的规模下,也碰到了一些任务负载不均,不够稳定,计算效率不高等问题,我们对此都做了部分优化和重构。
通过对开源实现的改造,字节跳动的图计算系统已经在线上支撑了多条产品线的计算任务,最大规模达到数万亿边、数千亿点的世界级超大图,这是业内罕见的。同时,面对不断增长的业务,并且我们还在持续扩大系统的边界,来应对更大规模的挑战。
自定义算法实现
在常见图计算算法之外,字节跳动多元的业务中,有大量的其他图算法需求以及现有算法的改造需求,比如需要实现更适合二分图的 LPA 算法,需要改造 PageRank 算法使之更容易收敛。
由于当前图计算系统暴露的 API 还没有非常好的封装,使得编写算法的用户会直接感知到底层的内部机制,比如不同的通信模式、图表示方式等,这固然方便了做图计算算法实现的调优,但也导致业务同学有一定成本;另外,因为涉及超大规模数据的高性能计算,一个细节(比如 hotpath 上的一个虚函数调用,一次线程同步)可能就对性能有至关重要的影响,需要业务同学对计算机体系结构有一定了解。基于上述两个原因,目前算法是图计算引擎同学和图计算用户一起开发,但长期来看,我们会封装常用计算算子并暴露 Python Binding ,或者引入 DSL 来降低业务的学习成本。
3.4 未来展望
面对字节跳动的超大规模图处理场景,我们在半年内快速开启了图计算方向,支持了搜索、风控等多个业务的大规模图计算需求,取得了不错的进展,但还有众多需要我们探索的问题:
- 从全内存计算到混合存储计算:为了支持更大规模的数据量,提供更加低成本的计算能力,我们将探索新型存储硬件,包括 AEP / NVMe 等内存或外存设备,扩大系统能力;
- 动态图计算:目前的系统只支持静态图计算,即对完整图的全量数据进行计算。实际业务中的图每时每刻都是在变化的,因此使用现有系统必须在每次计算都提供整张图。而动态图计算能够比较好地处理增量的数据,无需对已经处理过的数据进行重复计算,因此我们将在一些场景探索动态图计算;
- 异构计算:图计算系统属于计算密集型系统,在部分场景对计算性能有极高的要求。因此我们会尝试异构计算,包括使用 GPU / FPGA 等硬件对计算进行加速,以追求卓越的计算性能;
- 图计算语言:业务直接接触底层计算引擎有很多弊端,比如业务逻辑与计算引擎强耦合,无法更灵活地对不同算法进行性能优化。而通过图计算语言对算法进行描述,再对其编译生成计算引擎的执行代码,可以将业务逻辑与计算引擎解耦,能更好地对不同算法进行自动地调优,将性能发挥到极致。
4. 总结
随着字节跳动业务量级的飞速增长和业务需求的不断丰富,我们在短时间内构建了图存储系统和图计算系统,在实际生产系统中解决了大量的问题,但同时仍面临着巨大的技术挑战,我们将持续演进,打造业界顶尖的一栈式图解决方案。未来已来,空间广阔,希望更多有兴趣的同学加入进来,用有趣的分布式技术来影响几亿人的互联网生活。
5. 参考文献
- 1. Bronson, Nathan, et al. “{TAO}: Facebook’s distributed data store for the social graph.” Presented as part of the 2013 {USENIX} Annual Technical Conference ({USENIX}{ATC} 13). 2013.
- 2. Malewicz, Grzegorz, et al. “Pregel: a system for large-scale graph processing.” Proceedings of the 2010 ACM SIGMOD International Conference on Management of data. 2010.
- 3. Low, Yucheng, et al. “Distributed graphlab: A framework for machine learning in the cloud.” arXiv preprint arXiv:1204.6078 (2012).
- 4. Gonzalez, Joseph E., et al. “Powergraph: Distributed graph-parallel computation on natural graphs.” Presented as part of the 10th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 12). 2012.
- 5. Gonzalez, Joseph E., et al. “Graphx: Graph processing in a distributed dataflow framework.” 11th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 14). 2014.
- 6. Zhu, Xiaowei, et al. “Gemini: A computation-centric distributed graph processing system.” 12th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 16). 2016.
- 7. Kyrola, Aapo, Guy Blelloch, and Carlos Guestrin. “Graphchi: Large-scale graph computation on just a {PC}.” Presented as part of the 10th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 12). 2012.
- 8. Roy, Amitabha, Ivo Mihailovic, and Willy Zwaenepoel. “X-stream: Edge-centric graph processing using streaming partitions.” Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 2013.
- 9. Shun, Julian, and Guy E. Blelloch. “Ligra: a lightweight graph processing framework for shared memory.” Proceedings of the 18th ACM SIGPLAN symposium on Principles and practice of parallel programming. 2013.
- 10. McSherry, Frank, Michael Isard, and Derek G. Murray. “Scalability! But at what {COST}?.” 15th Workshop on Hot Topics in Operating Systems (HotOS {XV}). 2015.
- 11. Aditya Auradkar, Chavdar Botev, Shirshanka Das. “Data Infrastructure at LinkedIn “2012 IEEE 28th International Conference on Data Engineering