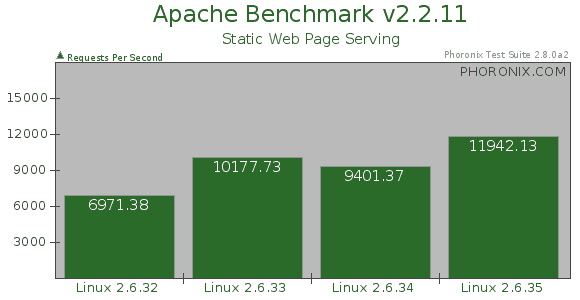
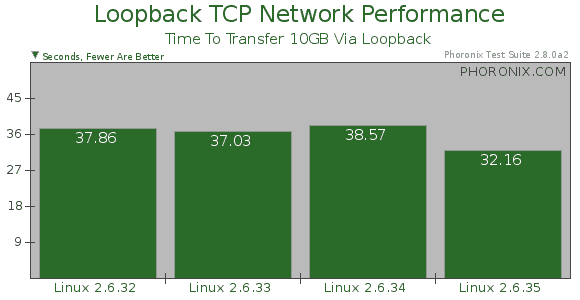
网络设备IO 瓶颈~ 现在可以关注下 Linux 2.6.35, 包含 Google 提交的两项改进网络处理性能的新特性: Receive packet steering, Receive flow steering, 在多核环境下并行处理网络负载!
Release Notes: http://kernelnewbies.org/Linux_2_6_35
Transparent spreading of incoming network traffic load across CPUs
Recommended LWN articles: "Receive packet steering" and "Receive flow steering"
Network cards have improved the bandwidth to the point where it's hard for a single modern CPU to keep up. Two new features contributed by Google aim to spread the load of network handling across the CPUs available in the system: Receive Packet Steering (RPS) and Receive Flow Steering (RFS).
RPS distributes the load of received packet processing across multiple CPUs. This solution allows protocol processing (e.g. IP and TCP) to be performed on packets in parallel (contrary to the previous code). For each device (or each receive queue in a multi-queue device) a hashing of the packet header is used to index into a mask of CPUs (which can be configured manually in /sys/class/net/<device>/queues/rx-<n>/rps_cpus) and decide which CPU will be used to process a packet. But there're also some heuristics provided by the RFS side of this feature. Instead of randomly choosing the CPU from a hash, RFS tries to use the CPU where the application running the recvmsg() syscall is running or has run in the past, to improve cache utilization. Hardware hashing is used if available. This feature effectively emulates what a multi-queue NIC can provide, but instead it is implement in software and for all kind of network hardware, including single queue cards and not excluding multiqueue cards.
Benchmarks of 500 instances of netperf TCP_RR test with 1 byte request and response show the potential benefit of this feature, a e1000e network card on 8 core Intel server goes from 104K tps at 30% CPU usage, to 303K tps at 61% CPU usage when using RPS+RFS. A RPC test which is similar in structure to the netperf RR test with 100 threads on each host, but doing more work in userspace that netperf, goes from 103K tps at 48% of CPU utilization to 223K at 73% CPU utilization and much lower latency.
Phoronix Test: http://www.phoronix.com/scan.php?page=article&item=linux_2635_i7&num=1